Redis学习笔记之实战篇
实战篇
短信登录
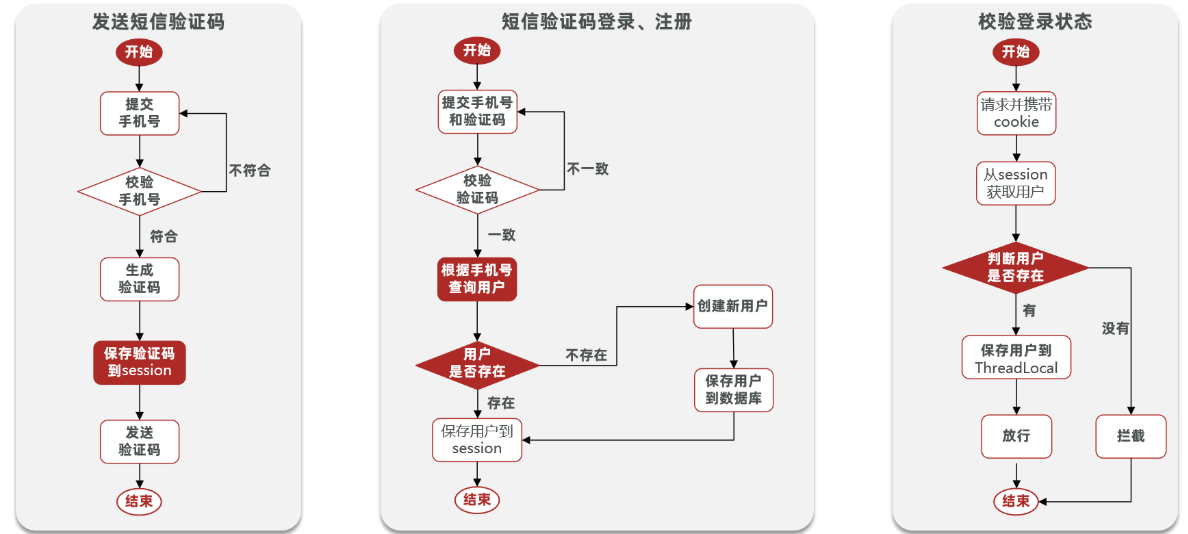
1. 思路分析
(1) 发送验证码:
用户在提交手机号后,会校验手机号是否合法,如果不合法,则要求用户重新输入手机号。如果手机号合法,后台此时生成对应的验证码,同时将验证码进行保存,然后再通过短信的方式将验证码发送给用户。
(2) 短信验证码登录、注册:
用户将验证码和手机号进行输入,后台从session中拿到当前验证码,然后和用户输入的验证码进行校验,如果不一致,则无法通过校验,如果一致,则后台根据手机号查询用户,如果用户不存在,则为用户创建账号信息,保存到数据库,无论是否存在,都会将用户信息保存到session中,方便后续获得当前登录信息。
(3) 校验登录状态:
用户在请求时候,会从cookie中携带者JsessionId到后台,后台通过JsessionId从session中拿到用户信息,如果没有session信息,则进行拦截,如果有session信息,则将用户信息保存到threadLocal中,并且放行。

2. 实现发送短信验证码功能
(1) 发送验证码
1 |
|
说明:
① session.setAttribute("code", code):核心是「保存校验凭证,实现用户绑定」
当用户输入手机号 + 验证码提交登录时,后端会执行 session.getAttribute("code"),取出这里存的验证码,和用户输入的对比 ——没有这行存储,后续登录就没有 “基准值” 可校验。
② log.debug("发送短信验证码成功,验证码:{}", code):核心是「调试排查,记录运行状态」
{}:SLF4J 的占位符,会自动把后面的 code 变量值替换到这个位置(比如最终打印:发送短信验证码成功,验证码:123456)。
(2) 登录
1 |
|
说明:
① 为什么校验的时候,要将cacheCode.toString(),不能直接比较?
session.getAttribute("code")的返回值是Object类型(这是HttpSessionAPI 的设计),所以变量cacheCode被声明为Object。loginForm.getCode()返回的是String类型,变量code是String。
② User user = query().eq(“phone”, phone).one(); query()的作用是什么?
- 这是 MyBatis-Plus 提供的一个方法,通常在继承了
ServiceImpl的 Service 层类中使用。 - 它的作用是:创建并返回一个
QueryWrapper查询条件构造器。
3. 实现登录拦截功能
(1) 拦截器代码
1 | public class LoginInterceptor implements HandlerInterceptor { |
说明:
在 LoginInterceptor 的 preHandle 方法中,当判断用户已登录后,会调用 UserHolder.saveUser(...),将用户信息存入当前处理请求的线程的 ThreadLocal 中。
(2) 让拦截器生效
1 |
|
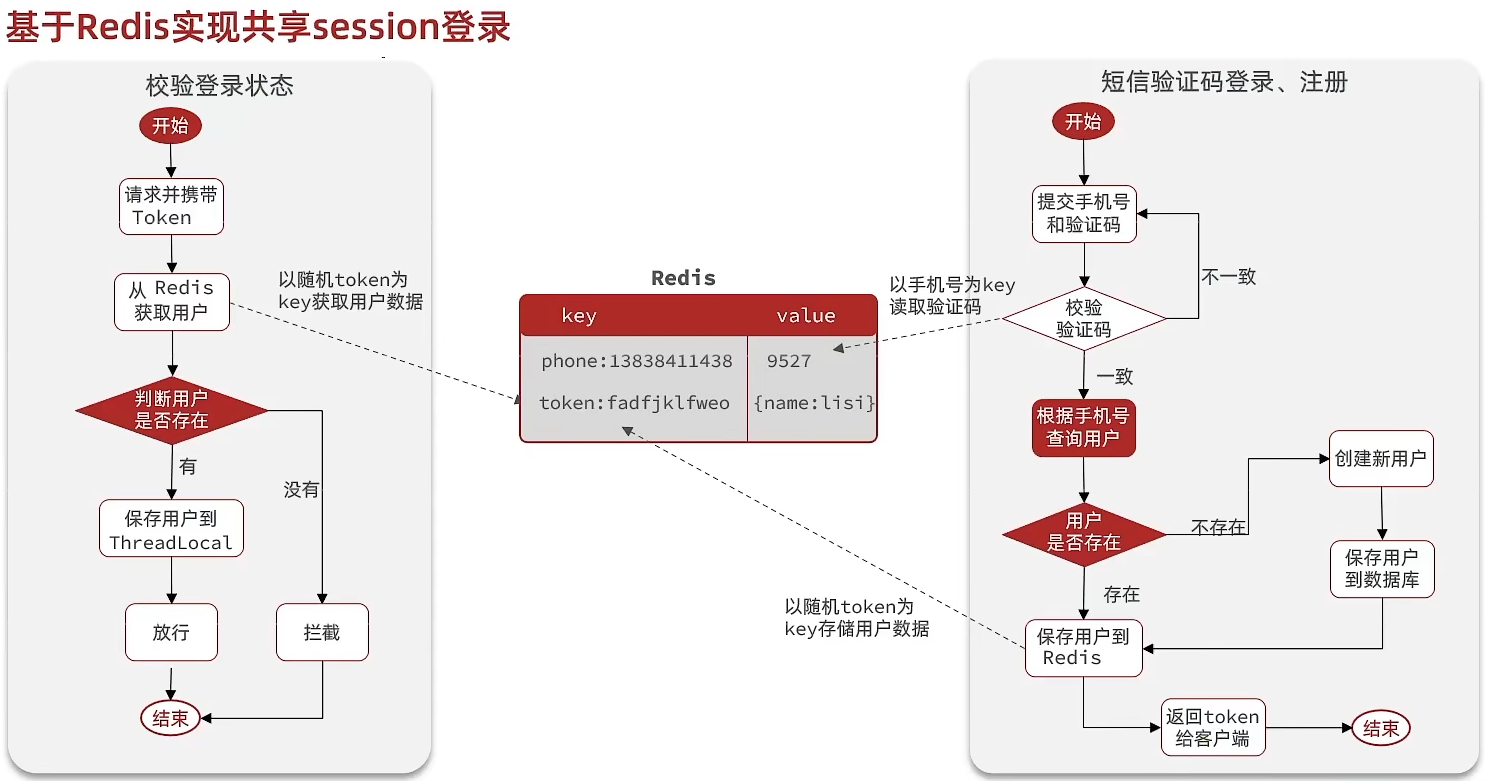
4. Redis代替session的业务流程
(1) 思路分析
当注册完成后,用户去登录会去校验用户提交的手机号和验证码,是否一致。如果一致,则根据手机号查询用户信息,不存在则新建,最后将用户数据保存到redis,并且生成token作为redis的key。当我们校验用户是否登录时,会去携带着token进行访问,从redis中取出token对应的value,判断是否存在这个数据,如果没有则拦截,如果存在则将其保存到threadLocal中,并且放行。
(2) 代码实现
① UserServiceImpl代码
1 |
|
说明:
1). UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
- 作用:把数据库查出来的
User实体(包含密码等敏感字段),复制为UserDTO(只保留 id、nickName、icon 等非敏感字段)。 - 核心意义:避免敏感信息(比如密码)泄露到前端 / Redis 中,保证数据安全。
2). Map<String, Object> userMap = BeanUtil.beanToMap(userDTO);
- 作用:把
UserDTO对象转换成Map集合(键是字段名,值是字段值)。 - 核心意义:Redis 的 Hash 结构只能接收「键值对」形式的数据,所以必须把对象转成 Map 才能存入。
3). setFieldValueEditor(...):强制把所有字段值转成字符串
- Redis 的 Hash 结构有个「死规矩」:键和值都必须是字符串类型,不支持 Long、Integer 等数字类型。
- ✅ 加了这个配置:
fieldValueEditor是个「编辑器」,它会遍历所有字段值,把不管是 Long、Integer 还是其他类型的值,都强制转成字符串 —— 比如 Long 的10086会变成字符串"10086",存入 Redis 后完全符合 Redis 的字符串要求,后续取值转换也不会报错。
4), stringRedisTemplate.expire(…)
给 Redis 中指定的 Key 设置「自动删除倒计时」,时间一到,Redis 就自动把这个 Key 和它对应的所有数据删掉。
5. 登录刷新问题
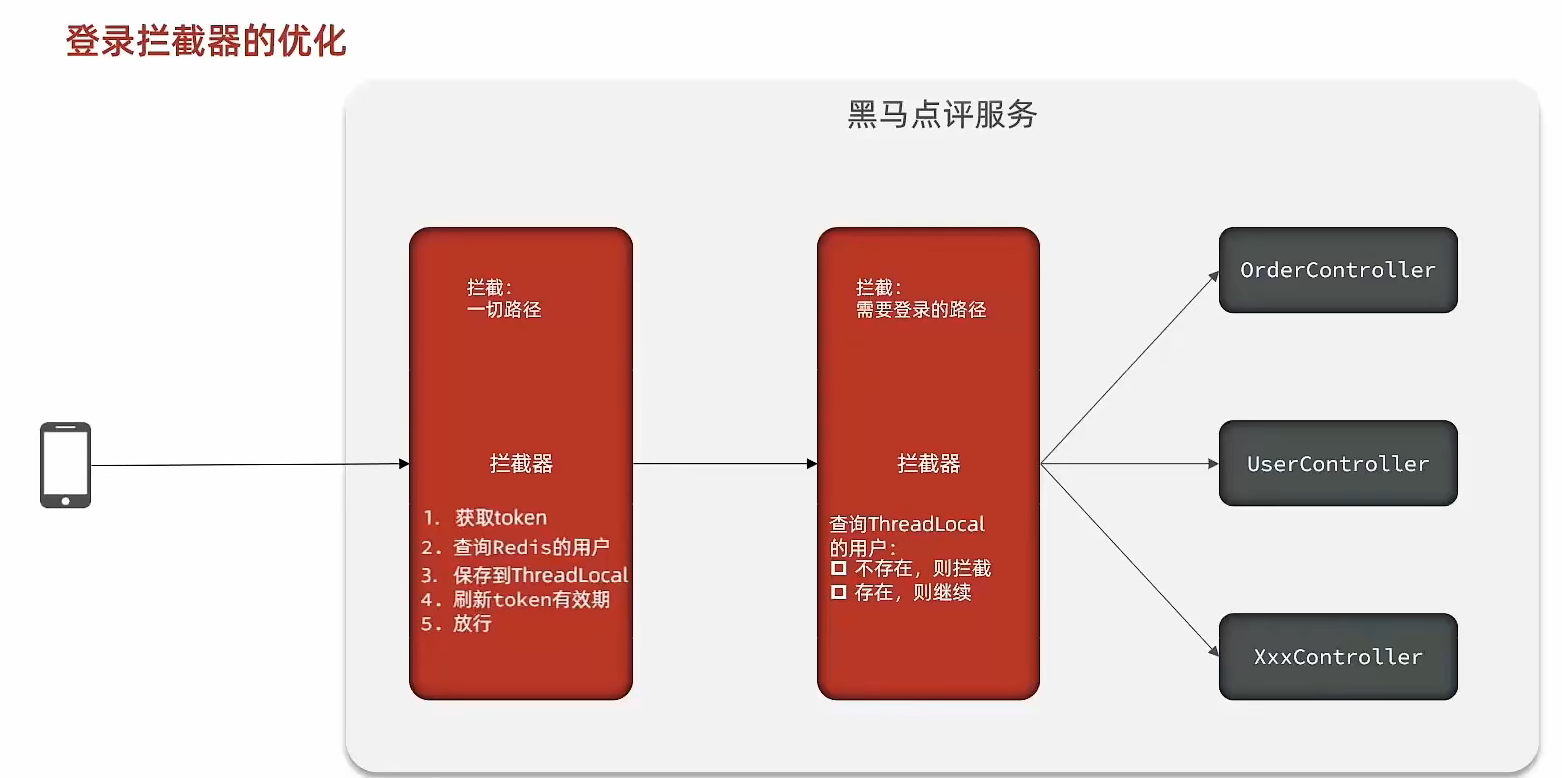
(1) 思路分析
之前的拦截器无法对不需要拦截的路径生效,那么我们可以添加一个拦截器,在第一个拦截器中拦截所有的路径,把第二个拦截器做的事情放入到第一个拦截器中,同时刷新令牌,因为第一个拦截器有了threadLocal的数据,所以此时第二个拦截器只需要判断拦截器中的user对象是否存在即可,完成整体刷新功能。
(2) 代码实现
① RefreshTokenInterceptor:做 “数据准备 + Token 续期”(永远放行)
1 |
|
② LoginInterceptor:只做 “权限拦截”(只判断,不干活)
1 |
|
商户查询缓存
1. 添加商户缓存
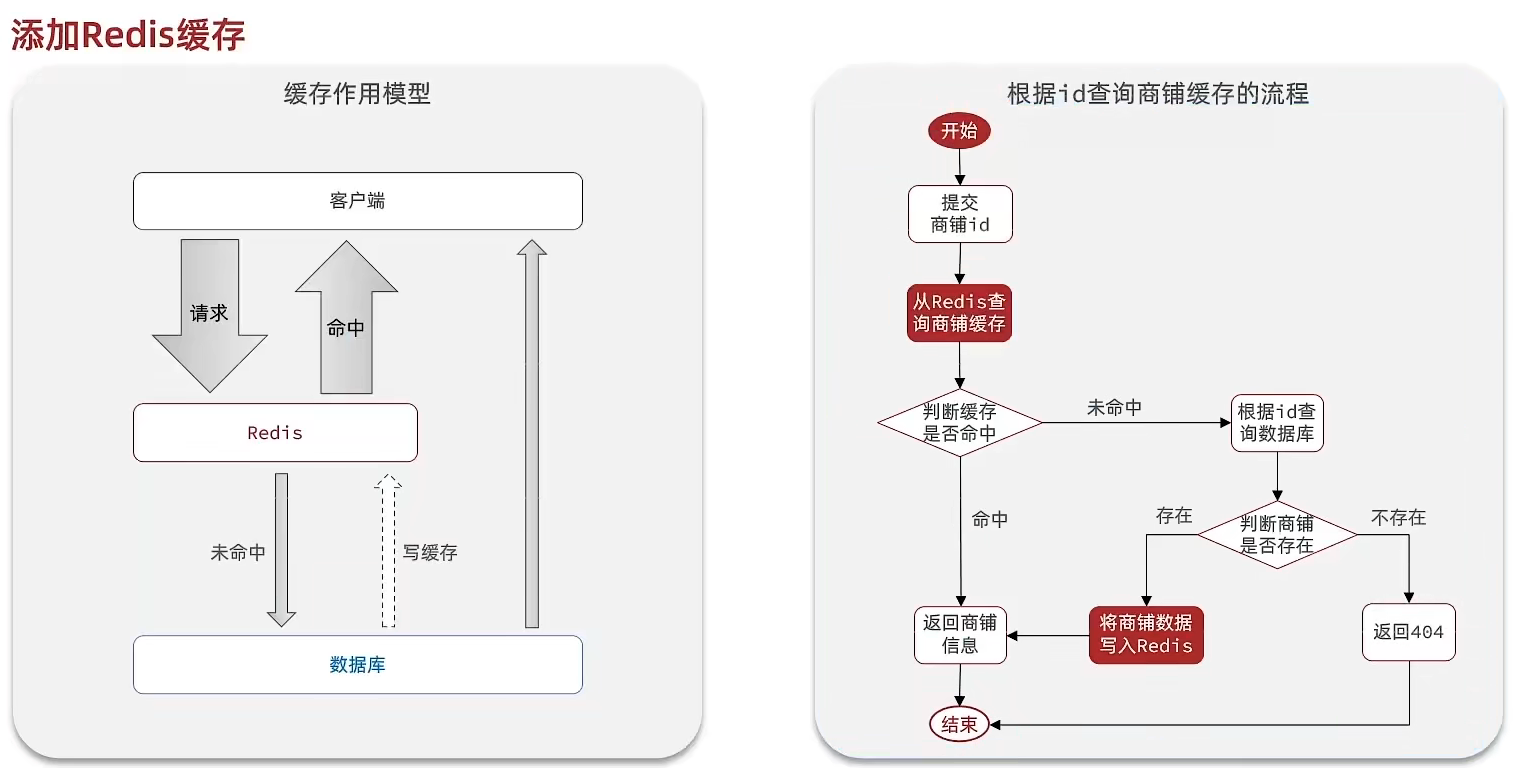
(1) 思路分析
标准的操作方式就是查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,如果缓存数据不存在,再查询数据库,然后将数据存入redis。
(2) 代码实现
1 |
|
说明:
① @Resource 能成功注入 StringRedisTemplate,核心原因是:Spring 容器中已经存在一个类型为 StringRedisTemplate 的 Bean,而 @Resource 注解可以根据名称或类型来查找并注入这个 Bean。Spring Boot 有一套「自动配置」逻辑,当你在项目中引入 spring-boot-starter-data-redis 依赖后,Spring 会自动加载 RedisAutoConfiguration 类(这个类是 Spring 框架自带的,不是你写的),里面会自动创建 StringRedisTemplate 和 RedisTemplate 两个 Bean。
② Shop shop = JSONUtil.toBean(shopJson, Shop.class); 为什么要转化类型?
- Redis 的存储限制:Redis 是一个键值对数据库,它只能存储字符串、数字等基础类型,不能直接存储 Java 对象。所以你在把
Shop存进 Redis 时,必须先用JSONUtil.toJsonStr(shop)把它转成 JSON 字符串(文本)才能存。 - Java 的业务需求:从 Redis 取出来后,必须把 JSON 字符串还原成
Shop对象,才能在 Java 代码里正常使用。
2. 缓存更新策略
(1) 三种策略
**① 内存淘汰:**redis自动进行,当redis内存达到咱们设定的max-memery的时候,会自动触发淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式)
**② 超时剔除:**当我们给redis设置了过期时间ttl之后,redis会将超时的数据进行删除,方便咱们继续使用缓存
**③ 主动更新:**我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题
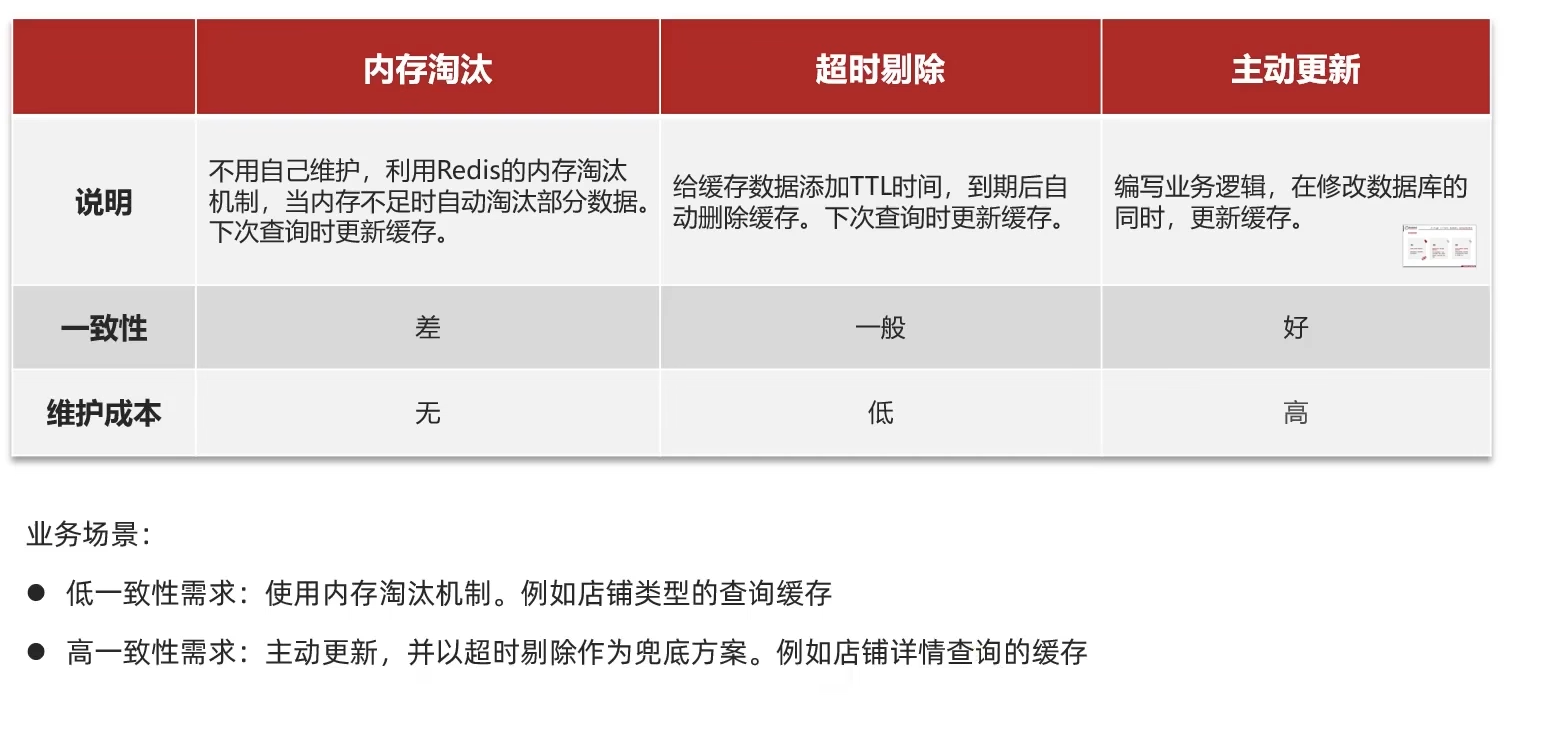
(2) 先操作缓存还是先操作数据库?
答案:应该先操作数据库。
左边「先删缓存,再更数据库」的并发问题(旧值 10、新值 20)
① 初始状态
- 数据库中值:10(旧值)
- Redis 缓存中值:10(旧值)
② 并发时序
| 时间顺序 | 线程 1(更新操作:把值改成 20) | 线程 2(查询操作) |
|---|---|---|
| 1 | 删除 Redis 缓存(缓存变为空) | - |
| 2 | - | 发起查询,缓存未命中 |
| 3 | - | 去数据库读取,拿到旧值 10 |
| 4 | - | 把旧值 10 写入 Redis 缓存 |
| 5 | 执行数据库更新,把值改成 20 | - |
③ 最终结果
- 数据库值:20(新值)
- Redis 缓存值:10(旧值)
- 后续所有查询都会直接读缓存的 10,直到缓存过期 / 被删除 —— 这就是缓存与数据库的数据不一致,本质是「缓存脏读」。
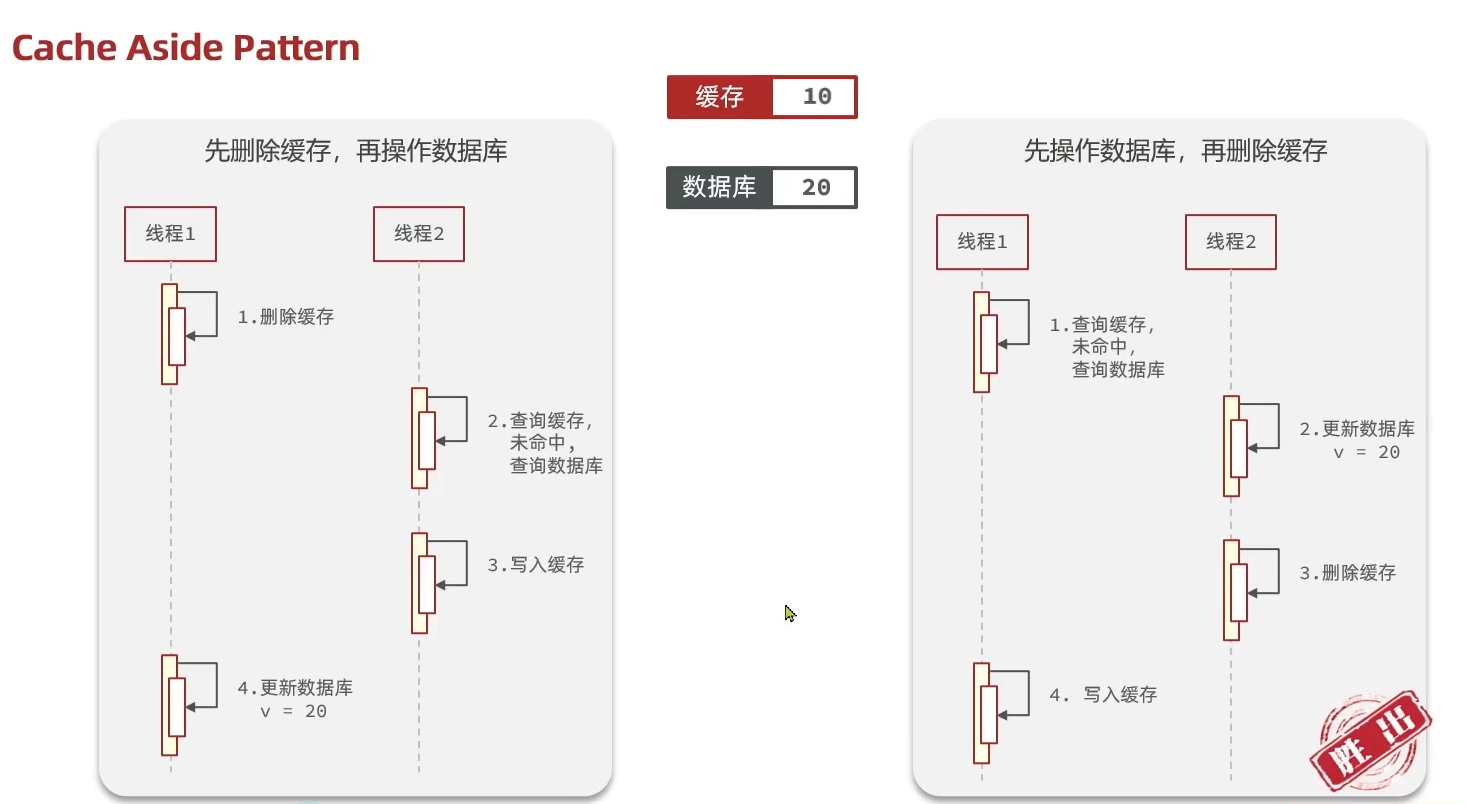
(3) 实现商铺和缓存与数据库双写一致
1 |
|
说明:
@Transactional 事务注解
- 作用:将整个方法包裹在一个数据库事务中,确保 “更新数据库” 和 “删除缓存” 这两个操作要么全部成功,要么全部失败(回滚)。
(4) 缓存穿透问题的解决思路
① 缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
② 常见的解决方案有两种:
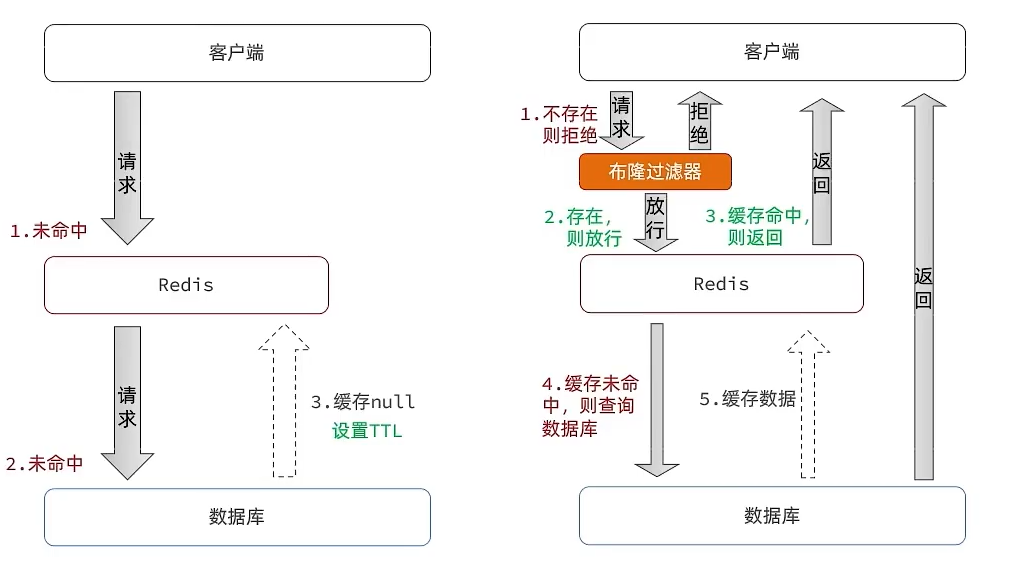
1). 缓存空对象
当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,简单的解决方案就是哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis中去。这样,下次用户过来访问这个不存在的数据,那么在 redis 中也能找到这个数据,就不会进入到数据库了。
2). 布隆过滤
布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中。
缺点:不存在一定不存在,存在可能不存在
(5) 编码解决商品查询的缓存穿透问题
重点代码
1 | if (shopJson != null) { |
说明:
① 先明确两个前置条件:
StrUtil.isNotBlank(shopJson):判断字符串非空且非空白(即shopJson不是null、不是""、不是全空格);- 前一行已经判定
StrUtil.isNotBlank(shopJson) == false,说明shopJson只有两种可能:null或""(空字符串)。
② 这行 if (shopJson != null):说明 shopJson 是 ""(空字符串)—— 这个 "" 是你之前主动存入 Redis 的「空对象标记」(对应代码里 stringRedisTemplate.opsForValue().set(key, "", ...))。
③ 逻辑意义:
- 如果 Redis 里存的是
"",说明之前已经查过这个 ID 的店铺,数据库里根本没有; - 此时直接返回 “店铺不存在”,不用再查数据库,避免恶意请求(比如传不存在的 ID)反复穿透到数据库,这就是「缓存空对象防穿透」的核心逻辑。
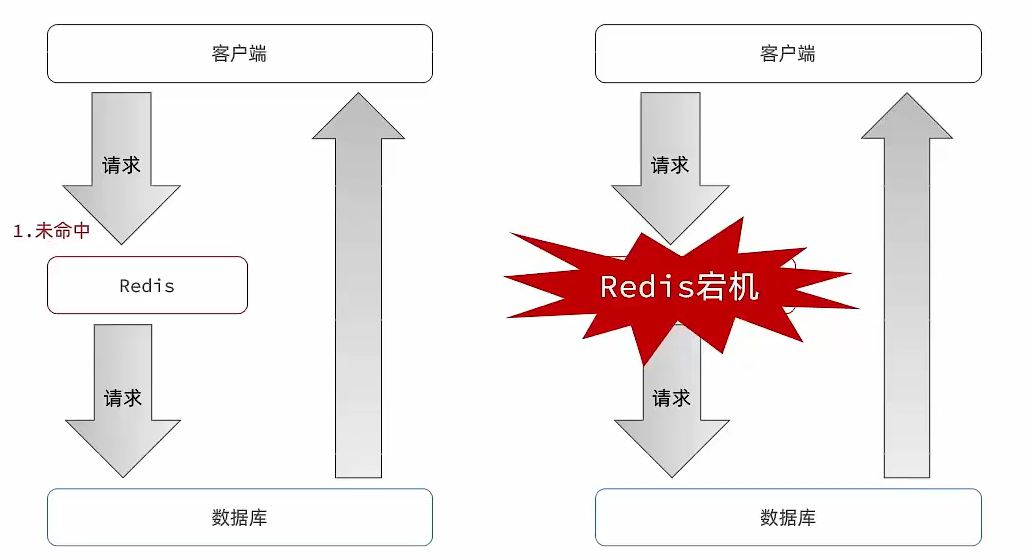
(5) 缓存雪崩问题及解决思路
① 缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
② 解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
(6) 缓存击穿问题及解决思路
① 缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
逻辑分析:假设线程1在查询缓存之后,本来应该去查询数据库,然后把这个数据重新加载到缓存的,此时只要线程1走完这个逻辑,其他线程就都能从缓存中加载这些数据了,但是假设在线程1没有走完的时候,后续的线程2,线程3,线程4同时过来访问当前这个方法, 那么这些线程都不能从缓存中查询到数据,那么他们就会同一时刻来访问查询缓存,都没查到,接着同一时间去访问数据库,同时的去执行数据库代码,对数据库访问压力过大。
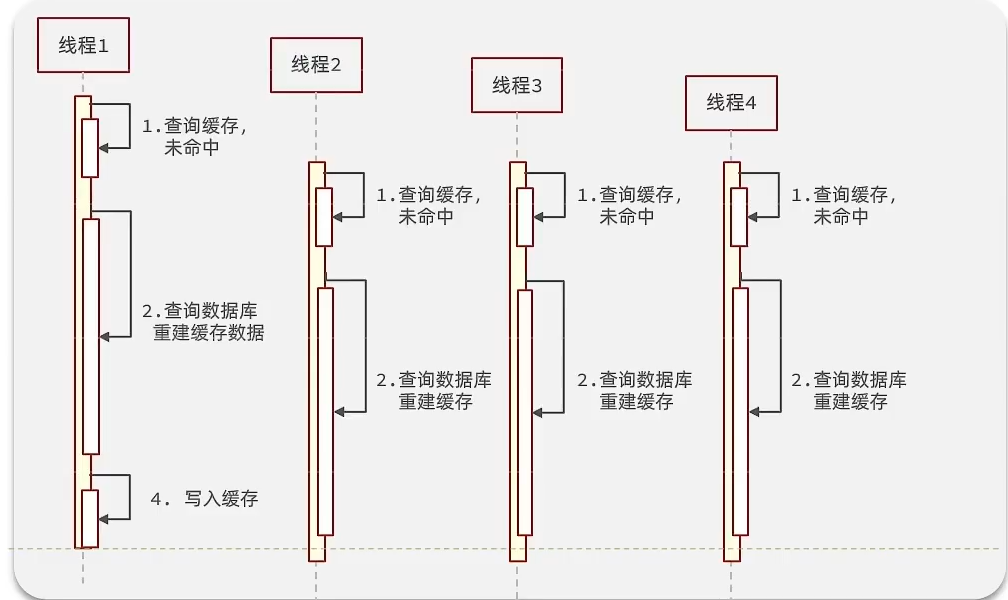
② 解决方案:
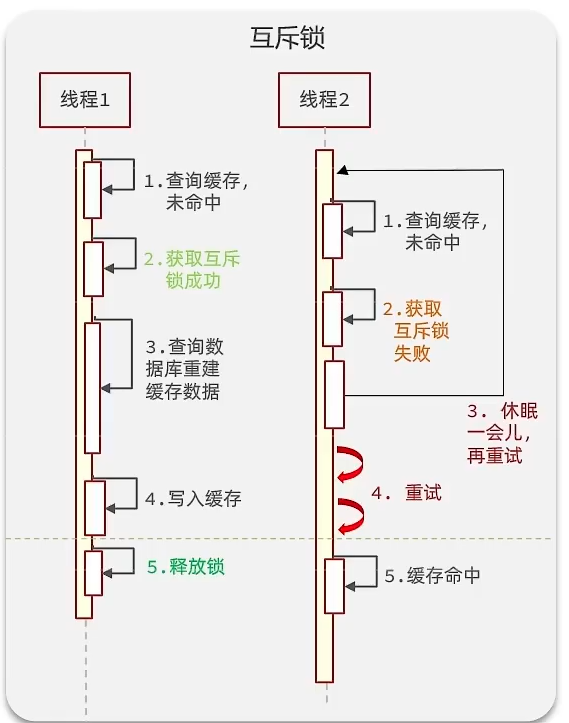
1). 互斥锁
假设现在线程1过来访问,它查询缓存没有命中,但是此时它获得到了锁的资源,那么线程1就会一个人去执行逻辑,假设现在线程2过来,线程2在执行过程中,并没有获得到锁,那么线程2就可以进行到休眠,直到线程1把锁释放后,线程2获得到锁,然后再来执行逻辑,此时就能够从缓存中拿到数据了。
2). 逻辑过期
我们把过期时间设置在redis的value中,注意:这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理。假设线程1去查询缓存,然后从value中判断出来当前的数据已经过期了,此时线程1去获得互斥锁,那么其他线程会进行阻塞,获得了锁的线程他会开启一个线程去进行以前的重构数据的逻辑,直到新开的线程完成这个逻辑后,才释放锁, 而线程1直接进行返回,假设现在线程3过来访问,由于线程线程2持有着锁,所以线程3无法获得锁,线程3也直接返回数据,只有等到新开的线程2把重建数据构建完后,其他线程才能走返回正确的数据。
这种方案巧妙在于,异步的构建缓存,缺点在于在构建完缓存之前,返回的都是脏数据。
(7) 利用互斥锁解决缓存击穿问题
① 思路分析
核心思路就是利用redis的setnx方法来表示获取锁,该方法含义是redis中如果没有这个key,则插入成功,返回1,在stringRedisTemplate中返回true,如果有这个key则插入失败,则返回0,在stringRedisTemplate返回false,我们可以通过true,或者是false,来表示是否有线程成功插入key,成功插入的key的线程我们认为他就是获得到锁的线程。
② 代码实现
1 | private boolean tryLock(String key) { |
说明:
① setIfAbsent(key, "1", 10, TimeUnit.SECONDS):Redis 的SETNX命令(不存在则设置),实现分布式锁:
- 如果 key 不存在,设置 key=1,过期时间 10 秒,返回
true(加锁成功); - 如果 key 已存在,返回
false(加锁失败); - 注意:返回值是
Boolean(包装类),可能为 null(比如 Redis 连接超时 / 异常);
② 为什么不用直接 return flag?
直接 return 可能出现NullPointerException(比如 flag=null 时),这个工具类帮你做了空值兜底,保证返回的是 boolean(基本类型),更安全。
(8) 利用逻辑过期解决缓存击穿问题
① 思路分析
当用户开始查询redis时,判断是否命中,如果没有命中则直接返回空数据,不查询数据库,而一旦命中后,将value取出,判断value中的过期时间是否满足,如果没有过期,则直接返回redis中的数据,如果过期,则在开启独立线程后直接返回之前的数据,独立线程去重构数据,重构完成后释放互斥锁。
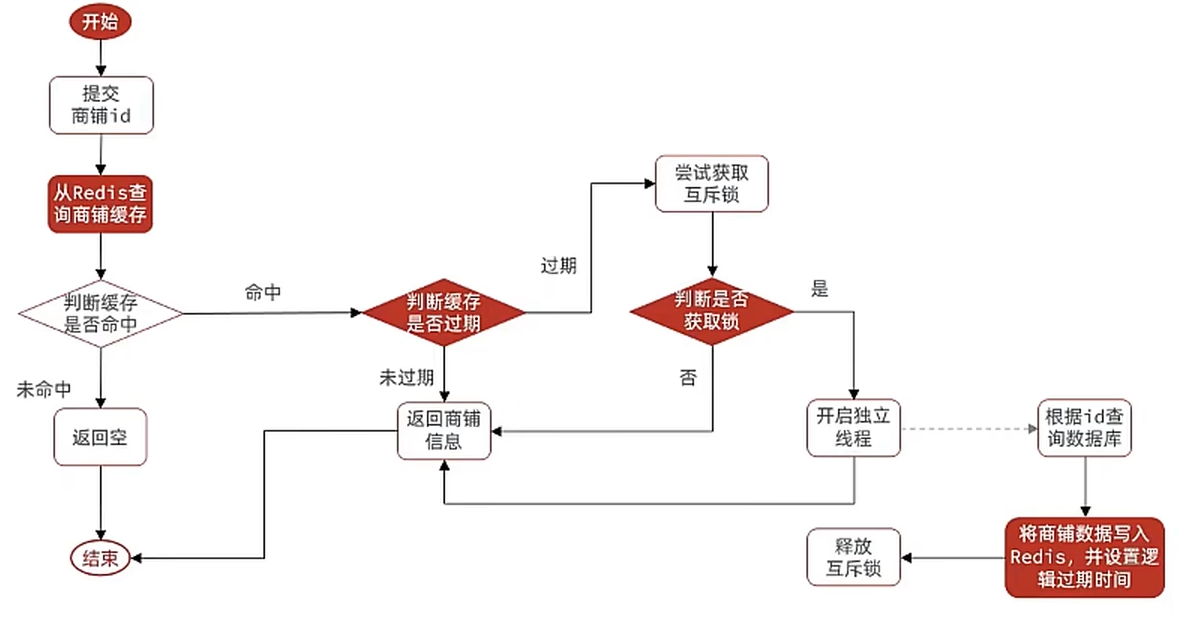
② 代码实现
1). 新建一个实体类
1 |
|
2). ShopServiceImpl
1 | private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10); |
说明:
① RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);
核心前提:RedisData 是一个自定义的封装类(你项目里肯定有这个类),作用是把 “业务数据(Shop)” 和 “逻辑过期时间” 打包存到 Redis 里。
② JSONObject data = (JSONObject) redisData.getData();
redisData.getData() 拿到的是 RedisData 里的 data 字段(类型是 Object),但这个字段实际存的是 Shop 对象的 JSON 格式数据,所以需要强转成 JSONObject(Hutool 工具类的 JSON 对象,也可以理解成 Map)。
(9) 封装Redis工具类
① 通用的缓存穿透解决方案
遵循 “先查缓存 → 缓存无则查数据库 → 数据库无则缓存空值 → 数据库有则缓存数据” 的逻辑,且通过泛型实现了 “通用化”
1 | public <R, ID> R queryWithPassThrough(String keyPrefix , ID id, Class<R> type, Function<ID, R> dbFallback, |
说明:
1). 先拆解方法签名
1 | // 泛型定义:<R, ID> (和上一版一致) |
R:代表返回值类型(可以是 Shop、User、Goods 等任意业务类);ID:代表主键类型(可以是 Long、Integer、String 等);
2). this::getById
语法含义:等价于一个 Lambda 表达式 (Long id) -> this.getById(id),本质是 “把查询数据库的方法作为参数传给通用方法”;
② 通用化、适配所有业务的缓存击穿解决方案(逻辑过期策略)
1 | // 1. 拼接通用缓存key(比如keyPrefix=cache:shop:,id=1 → key=cache:shop:1) |
说明:
1). dbFallback.apply(id) 是什么?
dbFallback是你调用方法时传入的 “数据库查询逻辑”,比如:
1 | // 调用时传入this::getById(根据id查店铺) |
dbFallback.apply(id) 就是执行this.getById(id),查数据库获取最新的店铺数据 —— 泛型 + 函数式接口让这个方法适配所有业务的数据库查询。
优惠券秒杀
1. 全局唯一ID
为了增加ID的安全性,我们不直接使用Redis自增的数值,而是拼接一些其它信息:

ID的组成部分:符号位:1bit,永远为0
时间戳:31bit,以秒为单位,可以使用69年
序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
2. Redis实现全局唯一Id
(1) RedisIdWorker
1 |
|
说明:
① String date = now.format(DateTimeFormatter.ofPattern(“yyyy:MM:dd”));
- 按日期拆分 Redis 计数器的 Key,避免单个 Key 的计数器值无限增大(比如累计到几十亿,既占内存又不方便管理);
- 让每个日期的计数器从
1开始,减少 ID 的长度(如果全局一个计数器,数值会快速变大); - 方便按日期统计 / 清理数据(比如删除 30 天前的计数器 Key)。
举个例子:订单业务的 Key,2026-03-11 是icr:order:2026:03:11,2026-03-12 就变成icr:order:2026:03:12,每天的计数器独立。
② return timestamp << COUNT_BITS | count.longValue();
这是核心的位运算逻辑,目的是把「相对时间戳」和「每日计数器」拼接成一个完整的 ID。
timestamp << COUNT_BITS:把timestamp(相对时间戳)左移 32 位,放到 64 位long的高位区域;比如timestamp=100,左移 32 位后变成100 * 2^32(二进制就是 100 后面跟 32 个 0);count.longValue():把 Redis 返回的计数器值转为long(因为返回的是Long包装类);|(按位或):把高位的时间戳和低位的计数器拼接成一个数(因为两部分的二进制位不重叠,按位或等价于拼接)。
(2) 测试类
1 |
|
说明:
CountDownLatch 的工作原理:
- 你(主线程)要统计 300 个工人(子线程)完成 “每人生产 100 个零件(生成 100 个 ID)” 的总耗时;
- 你先给工人发了一个 “倒计时牌”(CountDownLatch (300)),初始数字是 300;
- 每个工人完成自己的 100 个零件后,就把倒计时牌数字减 1(
latch.countDown()); - 你站在旁边等(
latch.await()),直到倒计时牌数字变成 0(所有工人都完成),才开始计算从开工到收工的总时间; - 如果没有这个倒计时牌,你可能刚安排完工人就看表,此时工人还在干活,统计的时间毫无意义。
3. 实现秒杀下单
(1) 思路分析
- 秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
- 库存是否充足,不足则无法下单
① 当用户开始进行下单,我们应当去查询优惠卷信息,查询到优惠卷信息,判断是否满足秒杀条件。
② 比如时间是否充足,如果时间充足,则进一步判断库存是否足够,如果两者都满足,则扣减库存,创建订单,然后返回订单id,如果有一个条件不满足则直接结束。
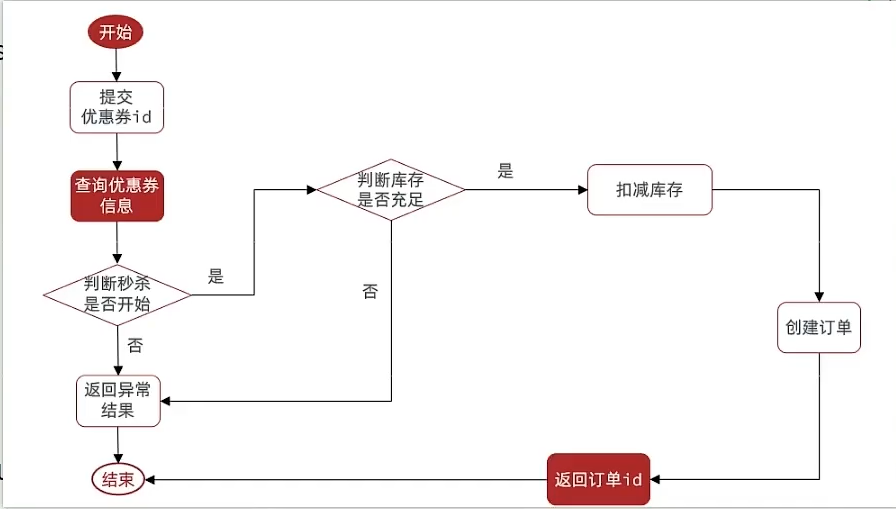
(2) 代码实现
VoucherOrderServiceImpl
1 |
|
说明:
① Resource private ISeckillVoucherService seckillVoucherService;
核心解释:这是 Spring 的依赖注入,目的是引入操作「秒杀优惠券表(SeckillVoucher)」的服务类。
ISeckillVoucherService:MyBatis-Plus 自动生成的服务接口,专门用于操作SeckillVoucher(秒杀优惠券)表,包含查询、修改、删除等方法;- 为什么需要它:秒杀逻辑的第一步是查询优惠券的秒杀时间、库存等信息(这些存在
SeckillVoucher表),所以必须注入这个服务来操作该表。
② 扣减库存的 update 链式调用
1 | seckillVoucherService.update() |
这是MyBatis-Plus 的链式更新语法,目的是扣减秒杀优惠券的库存,拆解每一步:
| 代码片段 | 作用 |
|---|---|
seckillVoucherService.update() |
初始化 MyBatis-Plus 的更新构造器(UpdateWrapper) |
.setSql("stock = stock - 1") |
设置要执行的 SQL 片段:将库存字段减 1(直接写 SQL 片段,而非 set (“stock”, 具体值),避免多线程下覆盖) |
.eq("voucher_id", voucherId) |
添加更新条件:只更新voucher_id等于传入的优惠券 ID 的记录 |
.update() |
执行最终的更新操作,对应 SQL:UPDATE seckill_voucher SET stock = stock - 1 WHERE voucher_id = ? |
4. 库存超卖问题分析
(1) 存在的问题
假设线程1过来查询库存,判断出来库存大于1,正准备去扣减库存,但是还没有来得及去扣减,此时线程2过来,线程2也去查询库存,发现这个数量一定也大于1,那么这两个线程都会去扣减库存,最终多个线程相当于一起去扣减库存,此时就会出现库存的超卖问题。
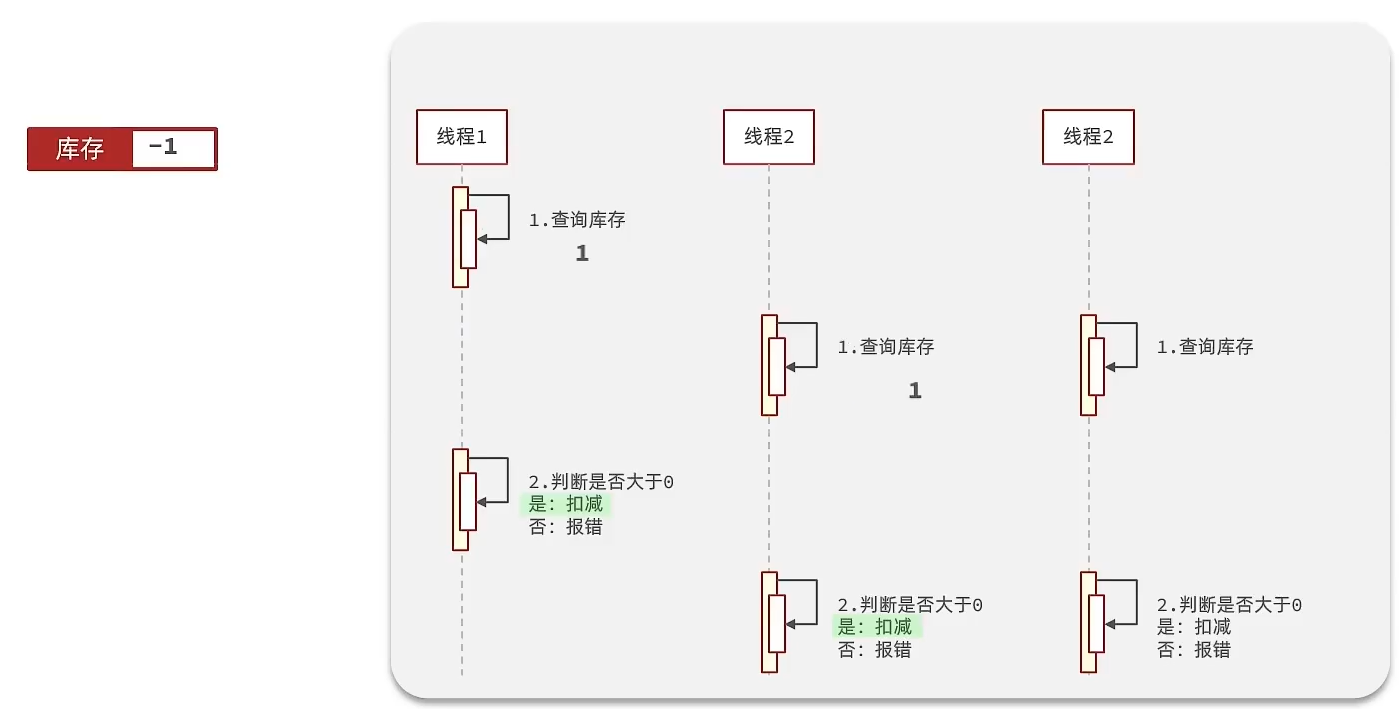
(2) 解决方案(我们采用乐观锁)
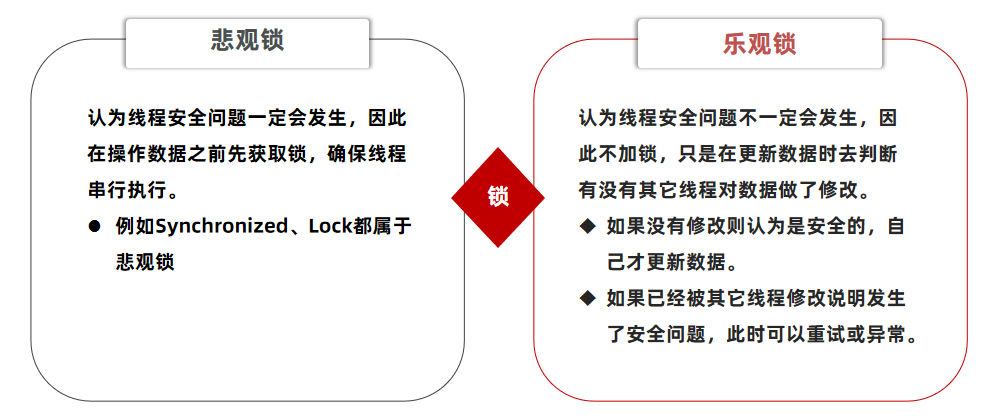
① 乐观锁:会有一个版本号,每次操作数据会对版本号+1,再提交回数据时,会去校验是否比之前的版本大1 ,如果大1 ,则进行操作成功。这套机制的核心逻辑在于:如果在操作过程中,版本号只比原来大1 ,那么就意味着操作过程中没有人对它进行过修改,它的操作就是安全的,如果不大1,则数据被修改过,乐观锁还有一些变种的处理方式比如cas
② 代码实现
1 | boolean success = seckillVoucherService.update() |
说明:
.gt("stock", voucher.getStock()) ✅ 核心防超卖逻辑
gt是greater than的缩写,意为大于。- 这是乐观锁 / 库存校验的关键:要求数据库中当前的库存值,必须大于代码中拿到的预期库存(
voucher.getStock())。 - 为什么能防超卖?多线程并发请求时,只有当数据库库存确实大于预期值时,才会执行扣减;如果某线程执行时库存已不足,该条件会直接失败,避免
stock变成负数。
5. 一人一单
(1) 版本1.0
1 |
|
说明:
synchronized 修饰整个方法 → 全局串行,性能崩溃
1 | public synchronized Result createVoucherOrder(Long voucherId) { |
❌ 所有用户的秒杀请求都要排队执行(比如 1000 个用户下单,只能一个接一个处理);
❌ 本来锁的目标是 “一人一单”(只锁单个用户),结果锁了所有用户,完全违背并发设计初衷。
(2) 版本2.0
1 |
|
说明:
锁在事务内 → 一人一单规则仍失效,锁的释放时机早于事务提交时机,导致 “一人一单” 规则被突破。
① @Transactional 注解的方法,其事务提交时机是「整个方法执行完毕、返回结果后」,而 synchronized 锁的释放时机是「代码块执行完毕」。
② 真实执行时序(以同一个用户的两个并发请求为例):
1 | 线程A(用户1)执行步骤: |
最终结果:用户 1 会创建两个订单,“一人一单” 的核心规则完全失效。
(3) 版本3.0
1 | synchronized (userId.toString().intern()) { |
说明:
- 保证事务生效:通过
proxy调用,Spring 代理对象会拦截方法,开启事务、提交 / 回滚,数据一致性得到保证。 - 保证一人一单:锁还在外层,释放锁前事务一定提交,并发安全性得到保证。
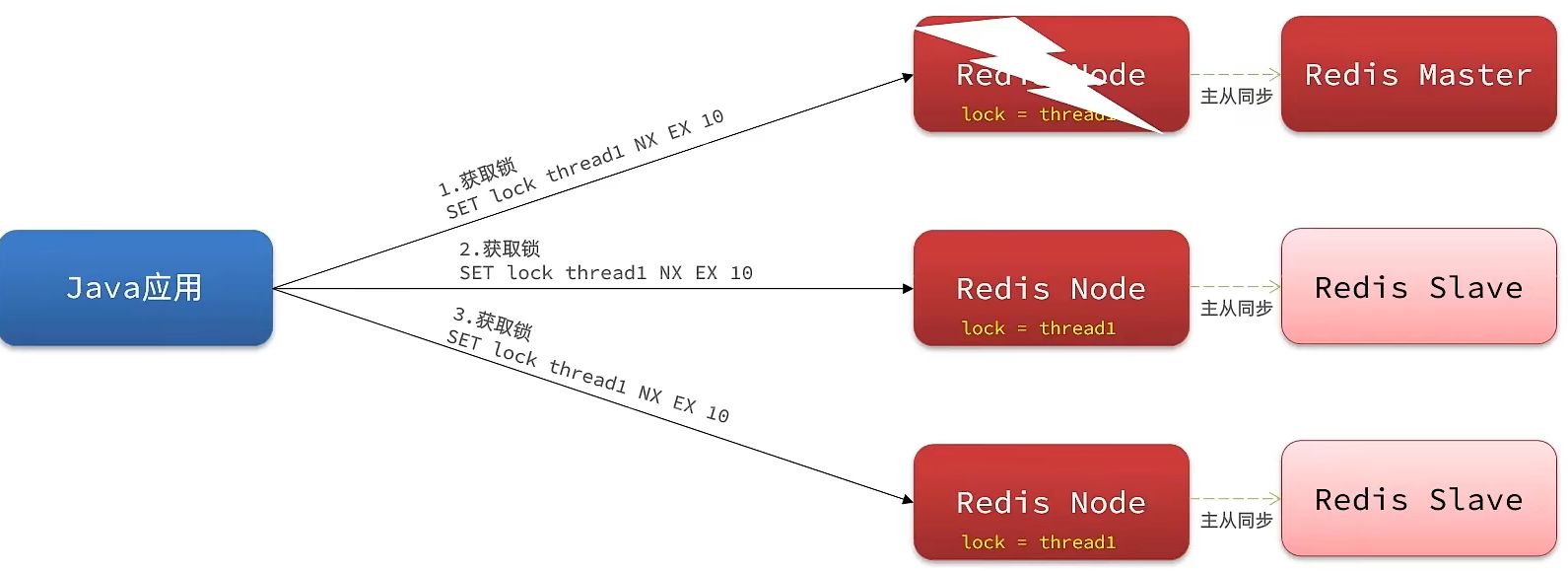
6. 集群环境下的并发问题
同一个用户(比如用户 100),同时发送请求到 服务器 A 和 服务器 B。
- 服务器 A 拿到锁,正在查库存 → 库存充足 → 准备扣减。
- 服务器 B 拿到锁,正在查库存 → 库存充足 → 准备扣减。
- 原因:服务器 A 的锁只认识服务器 A 里的线程,它根本不知道服务器 B 里还有个线程在抢同一个资源。
- 结果:两个服务器同时执行了扣减逻辑,导致了 超卖,且同一个用户买了 两份订单(一人多单)。
分布式锁
1. Redis 实现分布式锁版统一
(1) SimpleRedisLock
1 | private static final String KEY_PREFIX="lock:" |
说明:
① .setIfAbsent(KEY_PREFIX + name, threadId + “”, timeoutSec, TimeUnit.SECONDS);
1). setIfAbsent 对应 Redis 的 SETNX 命令,核心逻辑是:如果 key 不存在,则设置值并返回 true;如果 key 已存在,则直接返回 false—— 这是实现分布式锁 “互斥性” 的核心(保证同一时间只有一个线程能拿到锁)。
2). threadId + "" 的小细节,Thread.currentThread().getId() 返回的是 long 原始类型,而 Redis 操作的 value 必须是 String 类型。拼接空字符串是最简洁的语法糖,能将 long 强制转为 String,满足 setIfAbsent 的参数类型要求。等价效果:String.valueOf(threadId),但写法更简洁。
② 为什么自动拆箱有风险?Boolean.TRUE.equals(success) 好在哪?
1). 代码中 Boolean success = ... 定义的是包装类 Boolean 对象,如果直接写 return success;,会触发 自动拆箱(将 Boolean 转为 boolean 原始类型)。
- 当 Redis 操作异常 / 返回
null时,success会是null; - 此时拆箱过程会尝试把
null转为boolean,直接抛出NullPointerException,导致程序崩溃。
2). Boolean.TRUE.equals(success) 的核心优势
Boolean.TRUE是 Boolean 类的单例常量,调用其equals()方法时,内部自带 null 校验逻辑;- 无论
success是null、Boolean.FALSE还是Boolean.TRUE,都能安全返回结果:
success 取值 |
return success;(直接拆箱) |
return Boolean.TRUE.equals(success); |
|---|---|---|
null |
抛 NullPointerException |
返回 false |
Boolean.FALSE |
抛 NullPointerException |
返回 false |
Boolean.TRUE |
正常返回 true |
返回 true |
(2) 修改业务代码
1 |
|
2. Redis分布式锁误删情况说明
(1) 存在的问题
- 线程 1成功获取锁,开始执行业务
- 线程 1 遇到阻塞(比如 JVM GC 垃圾回收、CPU 繁忙),导致业务执行超时 → Redis 锁自动过期释放。
- 线程 2刚好来抢锁,成功获取锁,开始执行自己的业务。
- 线程 1恢复执行,业务做完了,它不知道锁已经过期被线程 2 拿走了,直接执行「删除锁」逻辑 → 误删线程 2 的锁。
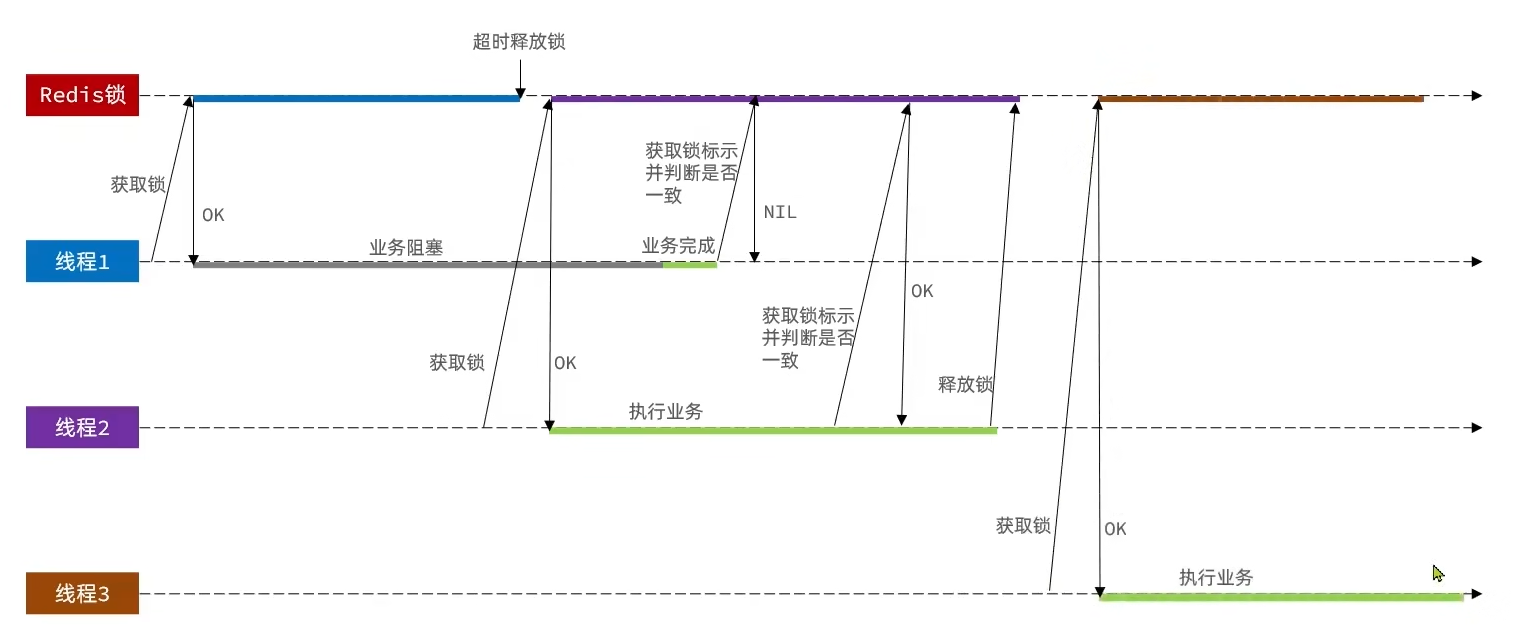
(2) 解决方案
① 核心逻辑:在存入锁时,放入自己线程的标识。在删除锁时,判断当前这把锁的标识是不是自己存入的,如果是,则进行删除,如果不是,则不进行删除。
② 代码实现
加锁
1 | private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-"; |
释放锁
1 | public void unlock() { |
3. 分布式锁的原子性问题
我们结合线程 1、线程 2 的动作,一步步拆解:
| 时间节点 | 线程 1 动作 | 线程 2 动作 | Redis 锁状态 | 关键变化 |
|---|---|---|---|---|
| 1 | 持有锁(value = 线程 1ID),执行业务 | 阻塞等待锁 | 存在(属于线程 1) | 线程 1 正常拿锁 |
| 2 | 执行到解锁步骤,先get锁,发现 value 是自己的 ID,进入if判断 |
等待 | 存在(属于线程 1) | 线程 1 完成 “验证”,还没执行 delete |
| 3 | 线程 1 突然卡顿 / GC(CPU 切换) | 无 | 锁过期自动释放 | 致命点!锁因为超时被 Redis 回收,线程 1 还没删 |
| 4 | 卡顿中 | 尝试抢锁,成功获取锁(value = 线程 2ID),开始执行业务 | 存在(属于线程 2) | 线程 2 拿到了锁,业务正在跑 |
| 5 | 线程 1 恢复执行 | 执行业务中 | 存在(属于线程 2) | 线程 1 从if里继续往下走,直接执行delete |
| 6 | 完成删除 | 业务中 | 被删空 | 线程 1 把线程 2 的锁删了!线程 2 的业务还没做完,锁没了 |
核心后果:线程 1 明明做了 “验证归属” 的判断,却依然误删了线程 2 的锁 —— 因为验证和删除中间被打断了。
4. 利用Java代码调用Lua脚本改造分布式锁
1 | private static final DefaultRedisScript<Long> UNLOCK_SCRIPT; |
说明:
① 静态代码块:加载 Lua 脚本
static final:脚本只需要加载一次,类加载时初始化,高效复用DefaultRedisScript:Spring Data Redis 提供的封装类,用来和 Redis 模板配合执行 Lua 脚本- 脚本位置:
unlock.lua放在项目resources文件夹下,里面就是 “判断 + 删除” 的逻辑
② unlock () 方法:执行 Lua 脚本释放锁
- 参数 1:
UNLOCK_SCRIPT→ 刚才加载好的脚本对象 - 参数 2:
Collections.singletonList(KEY_PREFIX + name)→ 脚本里的KEYS[1],就是锁的 key(比如lock:order) - 参数 3:
ID_PREFIX + Thread.currentThread().getId()→ 脚本里的ARGV[1],就是当前线程的唯一标识(用来和锁里存的 value 对比)
分布式锁-redission
1. 存在的问题
(1) 不可重入:
1 | // 方法A加了分布式锁 |
线程执行methodA拿到锁后,调用methodB时,再次尝试拿同一个锁,这时候分布式锁会认为 “锁已经被别人占了”,导致线程自己阻塞自己,形成死锁。
(2) 不可重试:
现在的setnx实现,线程尝试拿锁一次,如果失败(返回false),就直接结束了,没有 “再试一次” 的机制。但实际业务里(比如秒杀、订单创建),锁竞争往往是短暂的,线程应该可以重试几次,提高拿到锁的成功率。
(3) 超时释放:
我们给锁加了过期时间(比如 30 秒),本来是为了防止 “服务挂了锁不释放” 导致死锁,但带来了新问题:如果业务执行时间超过了锁的过期时间,锁会自动释放,这时候其他线程就能拿到锁,操作同一个资源,导致数据不一致。
(4) 主从一致性:
① Redis 主从集群的原理
- 主节点(Master):负责写操作(加锁、解锁)
- 从节点(Slave):负责读操作,主节点的数据会异步同步到从节点
- 如果主节点挂了,集群会把一个从节点升级为新的主节点
② 问题场景
- 线程 A 向主节点加锁成功,主节点还没把这个锁数据同步到从节点
- 主节点突然宕机了
- 集群选举一个从节点成为新主节点,但这个新主节点没有刚才的锁数据,认为锁不存在
- 线程 B 来拿锁,直接成功,这时候就出现了两个线程同时持有同一个锁的情况,锁失效,并发安全问题爆发。
2. Redission快速入门
(1) 配置Redisson客户端
1 |
|
(2) 如何使用Redission的分布式锁
1 |
|
(3) VoucherOrderServiceImpl
1 |
|
3. redission可重入锁原理
(1) 3 个核心参数
| 参数 | 含义 | 作用 |
|---|---|---|
KEYS[1] |
锁的大 key(锁名称) | 代表这把锁的整体,用来判断锁是否存在 |
ARGV[1] |
锁的过期时间(毫秒) | 防止锁死锁,即使客户端宕机也会自动释放 |
ARGV[2] |
锁的小 key(持有者标识) | 格式:客户端ID + ":" + 线程ID,用来判断锁是否属于当前线程 |
(2) 脚本的核心逻辑
1 | -- 步骤1:锁不存在 → 直接加锁 |
4. redission锁重试和WatchDog机制
(1) Lua 抢锁逻辑
| 条件 | 操作 | 返回值 | 含义 |
|---|---|---|---|
| 锁不存在 | 插入锁(Hash 结构),设置过期时间 | null |
抢锁成功 |
| 锁存在且属于当前线程 | 重入次数 + 1,刷新过期时间 | null |
可重入成功 |
| 锁存在且不属于当前线程 | 无操作 | 锁的剩余过期时间(ttl) | 抢锁失败 |
(2) lock() 核心抢锁流程
1 | long threadId = Thread.currentThread().getId(); |
说明:
① Long ttl = tryAcquire(-1, leaseTime, unit, threadId);
-1:是waitTime的默认值(表示无限等待,直到抢到锁);leaseTime:锁的过期时间(无参lock()时默认-1,带参lock(10, TimeUnit.SECONDS)时为 10);unit:时间单位(如TimeUnit.MILLISECONDS);threadId:当前线程 ID。
② 返回值 ttl:
null→ 抢锁 / 可重入成功;- 非 null 数字 → 锁被其他线程持有,返回锁的剩余过期时间(比如返回 20000 代表锁还有 20 秒过期)。
(3) WatchDog(看门狗)续约机制
1 | RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(waitTime, |
说明:
① tryLockInnerAsync(...) 的第二个参数:commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout()
- 含义:获取 Redisson 配置的「看门狗默认超时时间」,默认值是 30 秒(30000 毫秒);
- 作用:把锁的初始过期时间设为 30 秒(替代用户传入的
leaseTime)。
② if (ttlRemaining == null) { scheduleExpirationRenewal(threadId); }
- 逻辑:只有抢锁成功(
ttlRemaining=null),才调用scheduleExpirationRenewal(threadId); scheduleExpirationRenewal:核心作用是「启动看门狗续约线程」,是连接抢锁和续约的关键方法。
5. redission锁的MutiLock原理
(1) 存在的问题
我们去写命令,写在主机上, 主机会将数据同步给从机,但是假设在主机还没有来得及把数据写入到从机去的时候,此时主机宕机,哨兵会发现主机宕机,并且选举一个slave变成master,而此时新的master中实际上并没有锁信息,此时锁信息就已经丢掉了。
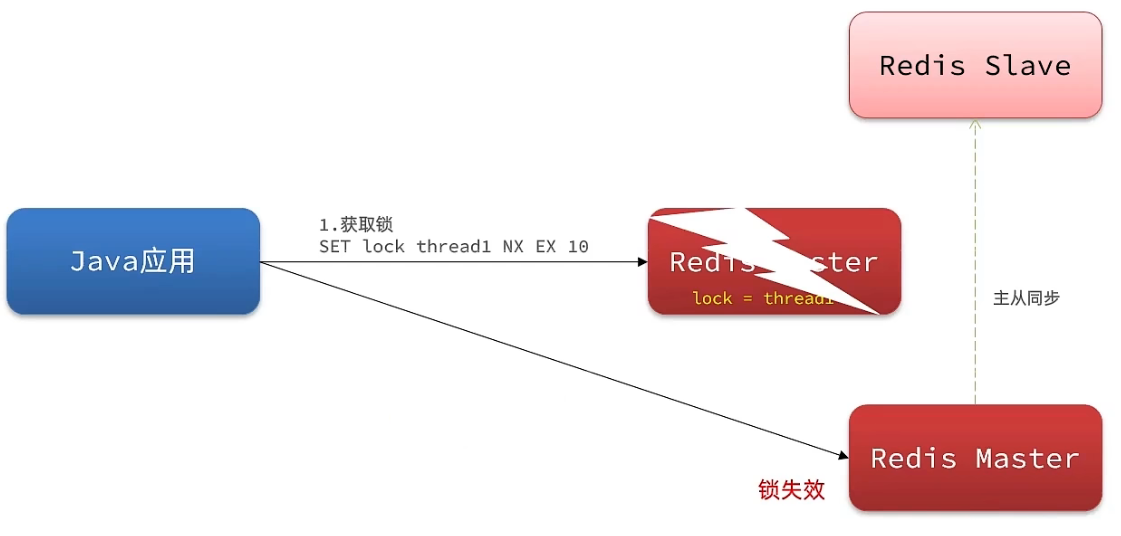
(2) 解决方案
为了解决这个问题,redission提出来了MutiLock锁,使用这把锁就不使用主从了,每个节点的地位都是一样的, 这把锁加锁的逻辑需要写入到每一个主丛节点上,只有所有的服务器都写入成功,此时才是加锁成功。假设现在某个节点挂了,那么它去获得锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性。
秒杀优化
1. 异步秒杀思路
(1) 当用户下单之后,判断库存是否充足只需要到redis中去根据key找对应的value是否大于0即可。如果不充足,则直接结束,如果充足,继续在redis中判断用户是否可以下单,如果set集合中没有这条数据,说明它可以下单,如果set集合中没有这条记录,则将userId和优惠卷存入到redis中,并且返回0,整个过程需要保证是原子性的,我们可以使用lua来操作。
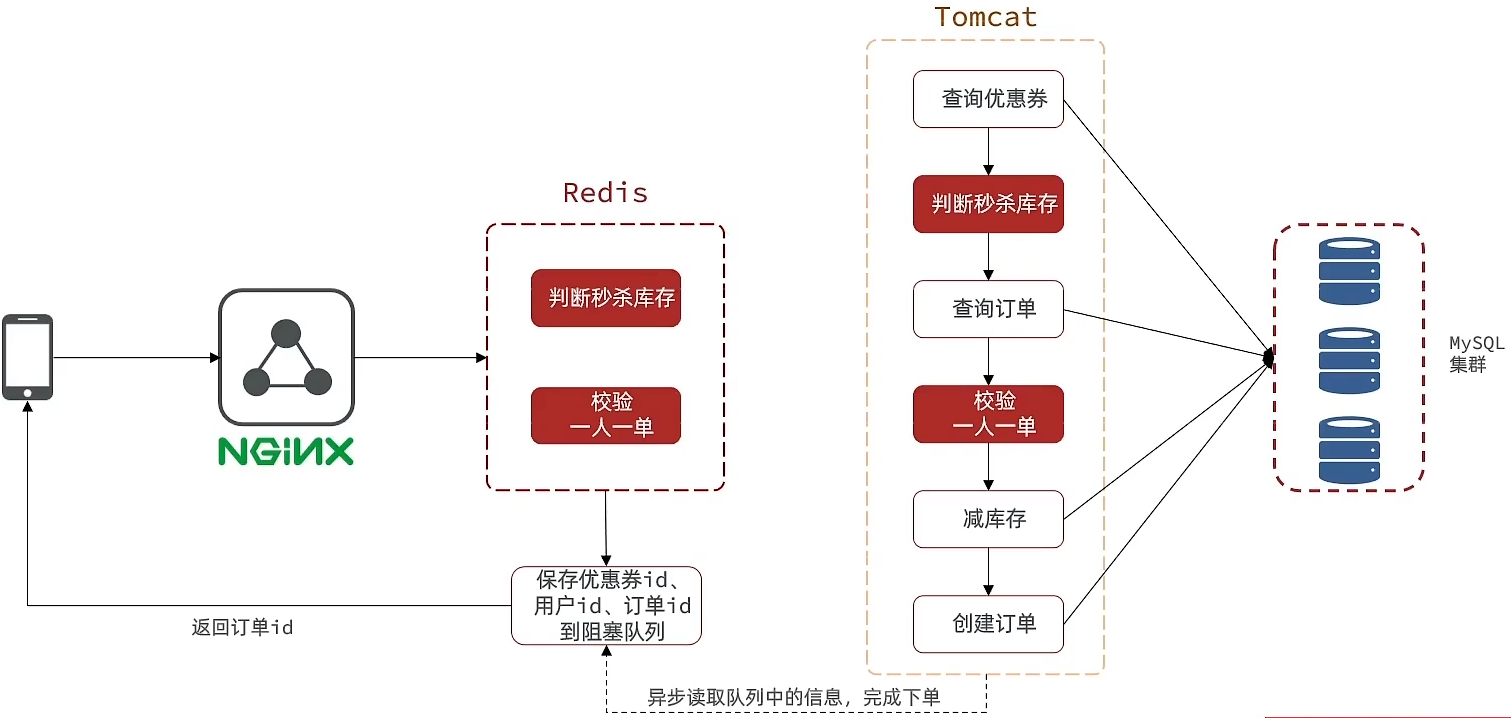
(2) 校验通过后,无需等待完整下单流程完成,直接给用户返回 “下单受理成功”(附带订单 ID),同时将下单任务丢入异步队列;后台单独线程消费异步队列中的任务,慢慢执行完整的数据库下单逻辑(创建订单、扣减库存等);前端通过返回的订单 ID,查询异步下单的最终结果(成功 / 失败)。
2. Redis完成秒杀资格判断
(1) 需求
- 新增秒杀优惠券的同时,将优惠券信息保存到Redis中
- 基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
- 如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
- 开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
(2) 代码实现
完整lua表达式
1 | -- 1.参数列表 |
说明:
① Lua 里的 .. 是什么
.. 是 Lua 语言的字符串拼接运算符,作用和 Java 里用 + 拼接字符串(比如 "a" + "b")完全一样,只是语法不同。
② if(tonumber(redis.call(‘get’, stockKey)) <= 0) then return 1 end
tonumber() 是 Lua 的内置函数,作用是把字符串类型的数字转成数值类型;
VoucherOrderServiceImpl
1 |
|
3. 基于阻塞队列实现秒杀优化
1 | //异步处理线程池 |
说明:
① private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
这是 Java 的线程池,Executors.newSingleThreadExecutor() 会创建一个「只有 1 个工作线程」的线程池 —— 所有任务都由这 1 个线程按顺序处理。
② @PostConstruct private void init() { SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler()); }
@PostConstruct:Spring 注解,作用是「当前类被 Spring 初始化完成后(项目启动时),立即执行这个方法」;
③ private class VoucherOrderHandler implements Runnable { … }
这是一个内部线程任务类,实现了 Runnable 接口(Java 中 “可被线程执行的任务” 都要实现这个接口),里面的 run() 方法是线程要执行的核心逻辑。
Postman测试方法
1. 发送验证码(不需要登录)
(1) 请求方式:POST
(2) 直连后端:http://localhost:8082/user/code?phone=13100000000
(3) 预期响应
1 | { |
2. 登录获取 token
(1) 请求方式:POST
(2) 直连后端:http://localhost:8082/user/login
(3) Body(选择 raw,格式 JSON):
1 | { |
注意:code 是第一步发送验证码后,在控制台日志里看到的 6 位数字
(4) 预期响应
1 | "1c3e03a8a5734dd1a8a5285c0d49a63c" |
这个字符串就是 token,复制保存下来
3. 测试登录状态(验证 token 是否有效)
(1) 请求方式:GET
(2) 直连后端:http://localhost:8082/user/me
(3) Headers:
authorization: 1c3e03a8a5734dd1a8a5285c0d49a63c
(4) 预期响应
1 | { |
4. 秒杀下单(需要登录)
(1) 请求方式:POST
(2) 直连后端:http://localhost:8082/voucher-order/seckill/10
(3) Headers:
authorization: 1c3e03a8a5734dd1a8a5285c0d49a63c
(4) Body:不需要
(5) 可能响应:
1 | { |
JMeter使用方法
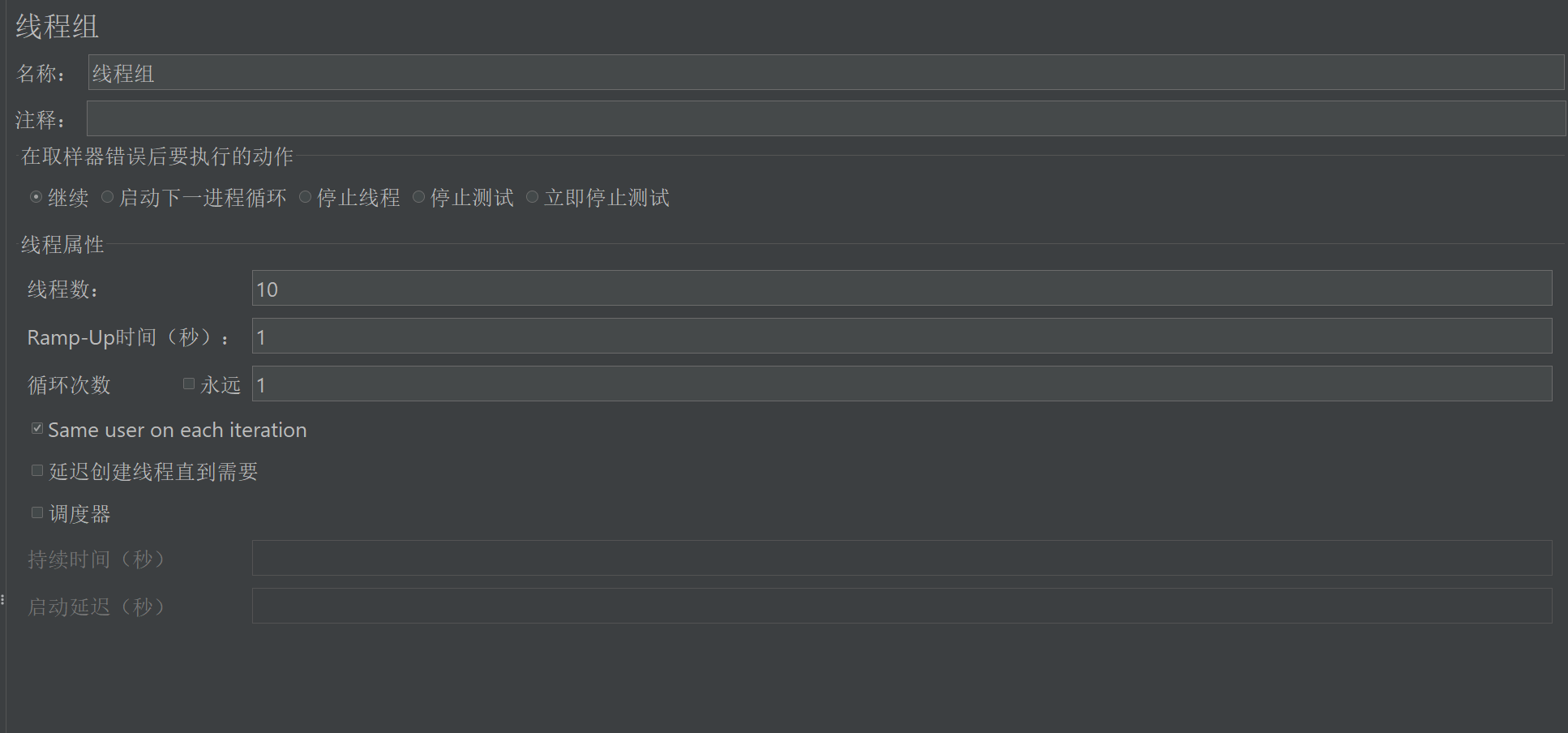
1. 添加线程组
(1) 右键 “测试计划” → 添加 → 线程(用户) → 线程组
(2) 配置
线程数(用户数):并发用户数(如 100)
Ramp-Up时间(秒):启动时间(如 10)
循环次数:每个线程执行次数(如 1)
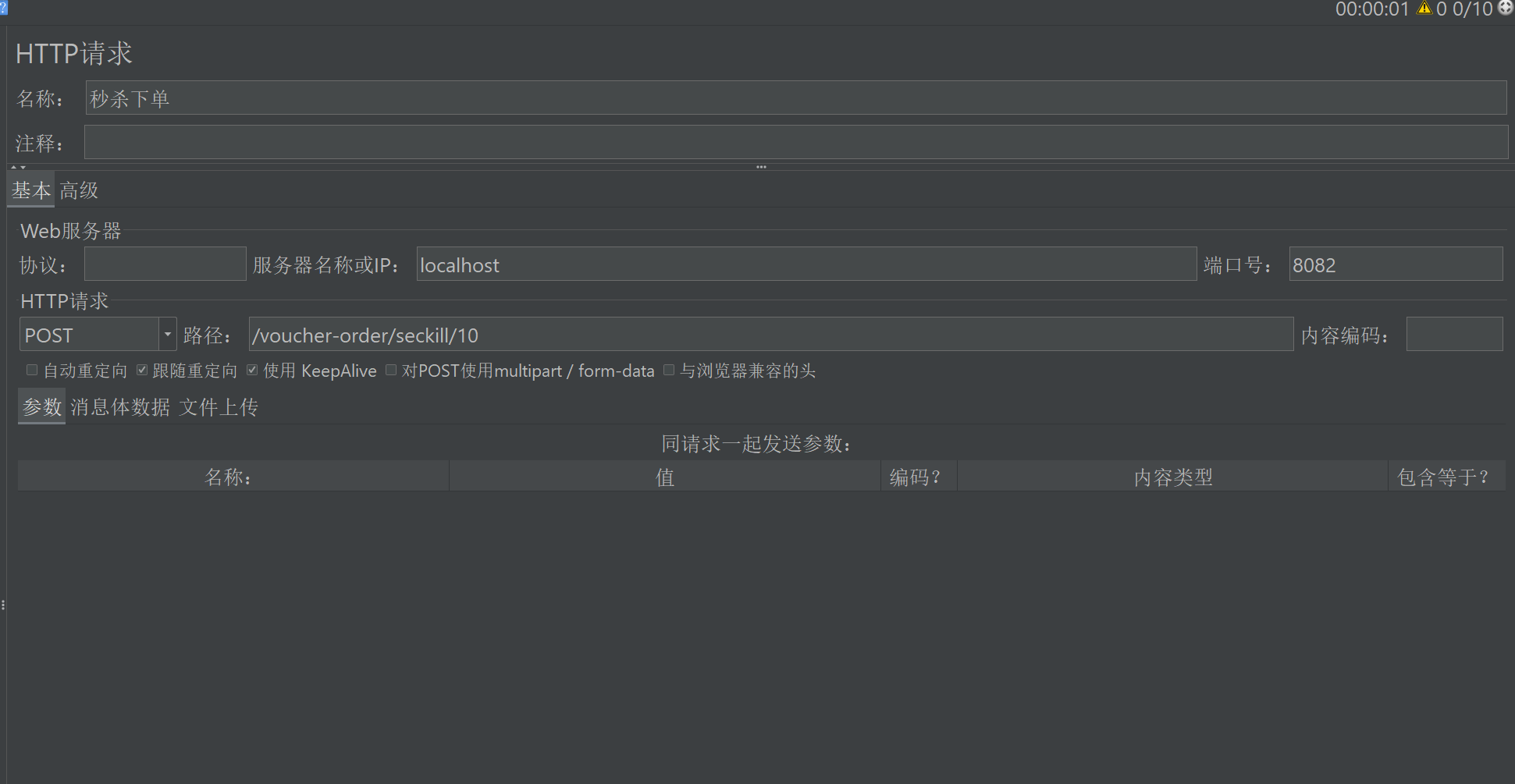
2. 添加 HTTP 请求
(1) 右键 “线程组” → 添加 → 取样器 → HTTP 请求
(2) 配置:
- 名称:秒杀下单(自定义)
- 服务器名称或IP:localhost(或后端服务器IP)
- 端口号:8081(或你的后端端口)
- 方法:POST
- 路径:/voucher-order/seckill/10(你的秒杀接口路径)
3. 添加 HTTP 信息头管理器
(1) 右键 “线程组” → 添加 → 配置元件 → HTTP 信息头管理器
(2) 配置:
- 名称:authorization
- 值:你的登录token(例如:1c3e03a8a5734dd1a8a5285c0d49a63c)
4. 添加监听器(查看结果)
右键 “线程组” → 添加 → 监听器 → 选择:
察看结果树:查看每个请求的详细响应(调试用)
汇总报告:查看统计信息(吞吐量、错误率等)
聚合报告:更详细的性能报告
5. 运行测试
点击顶部工具栏的绿色“启动”按钮
消息队列
1. 为什么使用消息队列
阻塞队列是 JVM 内存内的本地队列,只适合「单机、简单场景」,实际项目中处处受限:
(1) 只能单机使用,不支持分布式
阻塞队列存储在单个 JVM 进程内存中,多机集群部署时队列无法共享:不同服务器的阻塞队列相互隔离,任务无法在集群间负载均衡,导致部分机器任务堆积、部分机器空闲,资源利用率极低。
(2) 消息无持久化,宕机就丢
阻塞队列的任务仅存在内存中,服务重启、宕机或 OOM 时,未处理的消息会全部丢失:在秒杀等核心业务中,这会导致用户已成功下单但订单数据丢失,引发资损和客诉。
2. 认识消息队列
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息
3. 基于List实现消息队列(了解即可)
(1) 实现原理
队列是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。当队列中没有消息时,RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。

(2) 优缺点
① 优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
② 缺点:
- 无法避免消息丢失
- 只支持单消费者
3. 基于PubSub的消息队列(了解即可)
(1) 实现原理
SUBSCRIBE channel [channel] :订阅一个或多个频道
PUBLISH channel msg :向一个频道发送消息
PSUBSCRIBE pattern[pattern] :订阅与pattern格式匹配的所有频道
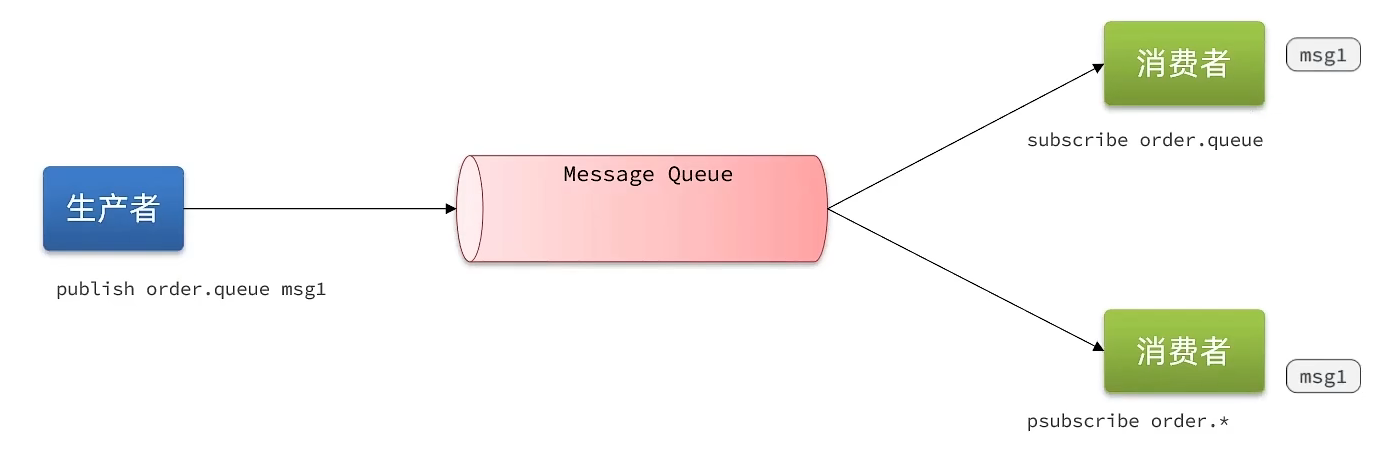
(2) 优缺点
① 优点:
- 采用发布订阅模型,支持多生产、多消费
② 缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
4. 基于Stream的消息队列(推荐)
(1) 发送消息:XADD 命令
1 | XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|ID field value [field value ...] |
说明:
key:消息队列名称,队列不存在时默认自动创建(NOMKSTREAM可禁止自动创建)。MAXLEN|MINID:用于限制队列的最大消息数量。*:让 Redis 自动生成消息 ID(格式:时间戳-递增数字,如1644805700523-0);也可手动指定 ID。- 消息内容:由多个
field value键值对组成(称为 Entry)。
示例:
1 | # 创建名为 users 的队列,发送消息 {name: jack, age: 21},自动生成 ID |
(2) 读取消息:XREAD 命令
1 | XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
说明:
① COUNT count:每次读取的最大消息数量。
② BLOCK milliseconds:阻塞模式,无消息时阻塞等待,超时后返回 (nil)。
③ STREAMS key:指定要读取的队列名称。
④ ID:起始读取 ID,仅返回大于该 ID 的消息:
0:从队列第一个消息开始读取。$:从队列最新消息开始读取。
示例:
① 读取历史消息:指定起始 ID 为 0,从队列第一条消息开始读取。
1 | XREAD COUNT 1 STREAMS users 0 |
② 阻塞读取最新消息:指定起始 ID 为 $,配合 BLOCK 实现阻塞等待,无消息时超时返回 (nil)
1 | XREAD COUNT 1 BLOCK 1000 STREAMS users $ |
(3) 关键注意点
使用 $ 读取最新消息时存在漏读风险:若处理当前消息期间,队列新增了多条消息,下次调用只会获取到最新的一条,中间新增的消息会被跳过。
5. 基于Stream的消息队列-消费者组
(1) 创建消费者组
1 | XGROUP CREATE key groupName ID [MKSTREAM] |
说明:
- key:队列名称
- groupName:消费者组名称
- ID:起始ID标示,$代表队列中最后一个消息,0则代表队列中第一个消息
- MKSTREAM:队列不存在时自动创建队列
(2) 删除指定的消费者组
1 | XGROUP DESTORY key groupName |
(3) 给指定的消费者组添加消费者
1 | XGROUP CREATECONSUMER key groupname consumername |
(4) 从消费者组读取消息:
1 | XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...] |
说明:
- group:消费组名称
- consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
- count:本次查询的最大数量
- BLOCK milliseconds:当没有消息时最长等待时间
- NOACK:无需手动ACK,获取到消息后自动确认(一般不要添加这个)
- STREAMS key:指定队列名称
- ID:获取消息的起始ID:
- “>”:从下一个未消费的消息开始
- 其它:根据指定id从pending-list中获取已消费但未确认的消息,例如0,是从pending-list中的第一个消息开始
(5) Redis Stream 消费者组可靠消费 的核心逻辑
1 | while(true){ |
说明:
① 必须 ACK:处理成功后,要调用 XACK 命令告诉 Redis “这条消息我处理完了”,消息会从 pending-list(未确认消息列表)中移除。
② Object msg = redis.call(“XREADGROUP GROUP g1 c1 COUNT 1 STREAMS s1 0”);
0代表从pending-list中读取已分配但未确认的消息,也就是之前处理失败的那条。- 这是为了不丢失消息,保证失败的消息会被反复重试,直到处理成功。
6. 基于Redis的Stream结构作为消息队列,实现异步秒杀下单
(1) 需求
- 创建一个Stream类型的消息队列,名为stream.orders
- 修改之前的秒杀下单Lua脚本,在认定有抢购资格后,直接向stream.orders中添加消息,内容包含voucherId、userId、orderId
- 项目启动时,开启一个线程任务,尝试获取stream.orders中的消息,完成下单
(2) VoucherOrderServiceImpl
1 | private class VoucherOrderHandler implements Runnable { |
说明:
1 | // 核心:从消息队列读取消息 |
stringRedisTemplate.opsForStream():拿到操作 Redis 消息队列的 “工具”,所有消息队列的读写都靠它。- 消费组(g1)+ 消费者(c1):可以理解为 “客服组 g1 里的客服 c1”,多个消费者能分摊处理队列消息,避免单线程扛不住。
stream.orders:是你的消息队列名称。block(2秒):队列没消息时不做空循环,等 2 秒再查,节省资源。
② 为什么 list 为空就 break?
list是从Pending List读取失败消息的结果,代码里设置了count(1)(每次只读 1 条);- 如果
list == null/空,说明 Pending List 里已经没有待重试的失败消息了(所有失败订单都处理完了); - 此时再继续死循环没有意义,所以
break跳出循环,结束本次失败消息的处理流程(等下次有新的失败消息时,这个方法会再次被调用)。
③ 为什么要 list.get(0)?
- 代码里
StreamReadOptions.empty().count(1)明确指定了「每次只读取 1 条消息」,所以list里最多只有 1 个元素; list.get(0)就是取出这唯一的一条失败消息,只有拿到这条消息,才能解析里面的订单数据(用户 ID、优惠券 ID),进而重新处理订单。
④ 为什么要调用 acknowledge 确认消息?
- 这是 Redis Stream 的「消息确认机制」,作用是告诉 Redis:这条失败的订单消息我已经重新处理成功了,请把它从 Pending List 中移除;
- 如果不确认(ACK):Redis 会一直把这条消息留在 Pending List 里,后续这个方法会反复读取这条消息,导致「同一个失败订单被重复处理」(比如用户一个订单被多次扣库存);
⑤ 这个方法的执行流程
1 | 1. 进入死循环,准备捞取失败订单; |
达人探店
1. 查看探店笔记
BlogServiceImpl
1 |
|
1 | private void queryBlogUser(Blog blog) { |
说明:
这个私有方法的核心作用是:根据博客(Blog)中的用户 ID,查询对应的用户信息,并把用户的「昵称」和「头像」两个核心字段填充到博客对象中,最终让博客对象包含发布者的展示信息(而非完整的用户对象),适配前端详情页只需要昵称 / 头像的展示需求。
2. 点赞功能
(1) 需求
- 同一个用户只能点赞一次,再次点击则取消点赞
- 如果当前用户已经点赞,则点赞按钮高亮显示(前端已实现,判断字段Blog类的isLike属性)
(2) 实现步骤
- 给Blog类中添加一个isLike字段,标示是否被当前用户点赞
- 修改点赞功能,利用Redis的set集合判断是否点赞过,未点赞过则点赞数+1,已点赞过则点赞数-1
- 修改根据id查询Blog的业务,判断当前登录用户是否点赞过,赋值给isLike字段
- 修改分页查询Blog业务,判断当前登录用户是否点赞过,赋值给isLike字段
(3) 代码实现
① 在Blog 添加一个字段
1 |
|
② 修改代码
1 |
|
3. 点赞排行榜
(1) BlogServiceImpl
1 |
|
说明:
① Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
作用:查询 指定博客的点赞集合 中,当前用户 是否存在,并返回它的分数。
业务判断:
score == null→ 用户没点赞score != null→ 用户已点赞
② stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());
作用:向 ZSet 中添加一个点赞用户,三个参数:
- 博客点赞的 key
- 点赞用户 ID
- 分数(当前时间戳)
关键点:
- ZSet 元素唯一 → 同一个用户重复点赞会被自动去重(完美适配「一人只能点一次赞」)
- 用时间戳当分数 → 后续可以直接按时间倒序,展示「最新点赞的用户列表」(普通 Set 做不到排序,这就是用 ZSet 的原因!)
(2) BlogController
1 |
|
(3) BlogService
1 |
|
说明:
① List
top5 是你从 Redis 取出来的 Set["1001", "1002", "1003"](字符串格式的用户 ID),数据库查询必须用数字类型(Long),所以要转换。
map(Long::valueOf)
map = 格式转换
1 | Long::valueOf` = 把字符串 `"1001"` 转成数字 `1001 |
② List
1). userService.query()
这是 MyBatis-Plus(MP)的链式查询
- 作用:开启一个查询构造器,不用写复杂的 SQL,用代码拼接查询条件
- 等价于:
SELECT * FROM user
2). .in(“id”, ids)
MP 的批量查询条件
- 含义:
id 在 ids 集合中 - 对应 SQL:
WHERE id IN (1001,1002,1003,1004,1005) - 作用:只查我们需要的前 5 个点赞用户,不查全表
3). .last (“ORDER BY FIELD (id,” + idStr + “)”)
先讲背景:
数据库用 IN 查询时,返回的用户是乱序的!比如你查 IN (1,2,3),数据库可能返回 3,1,2,会打乱 Redis 里点赞的先后顺序。
两个关键点:
- **
last()**MP 的方法:手动在 SQL 最后追加一段代码(这里用来加排序) - **
ORDER BY FIELD(id, 1,2,3,4,5)**MySQL 专属函数,作用:强制让结果按照我指定的 ID 顺序排序
举个例子:
idStr = "1001,1002,1003,1004,1005"- 拼接后 SQL:
ORDER BY FIELD(id,1001,1002,1003,1004,1005) - 结果:用户必须按 1001→1002→1003→1004→1005 的顺序返回完美对应 Redis 里的点赞先后顺序!
4). String idStr = StrUtil.join(“,”, ids);
StrUtil.join 是 hutool 工具类的拼接方法,作用:把一个集合 / 数组,用指定符号拼接成一个字符串
举个最直观的例子:
- 输入:
ids = [101, 102, 103] - 拼接符号:
, - 输出:
idStr = "101,102,103"
为什么要拼这个字符串?
为了给后面的 SQL 排序 用!数据库需要这种逗号分隔的格式。
好友关注
1. 关注和取消关注
(1) FollowController
1 | //关注 |
(2) FollowService
1 | 取消关注service |
说明:
| 字段 | 含义 |
|---|---|
userId |
当前登录用户(你自己) |
followUserId |
要关注 / 取关的用户(博主) |
tb_follow 表 |
专门存关注关系的表 |
isFollow |
true= 关注,false= 取关 |
① if (isFollow) → 关注(新增数据)
1 | // 新建一个【关注关系】对象 |
- **
Follow follow = new Follow();**数据库里有一张表叫tb_follow(关注表),我们要往表里加一条数据,就得先创建一个对应的对象。 - **
setUserId(userId)**填数据:关注的人是我(我是主动关注的一方)。 - **
setFollowUserId(followUserId)**填数据:我关注的人是他(对方是被关注的博主)。 - **
save(follow)**MyBatis-Plus 提供的方法,直接把这条关注数据插入数据库。
② else → 取关(删除数据)
1 | remove(new QueryWrapper<Follow>() |
new QueryWrapper
→ 删除条件
翻译:我不能乱删,必须告诉我删哪一行
2. 共同关注
(1) 代码实现
1 | // UserController 根据id查询用户 |
说明:
① @PathVariable 和 @RequestParam 的区别
@PathVariable(路径参数,写在 URL / 里的), @RequestParam 是 查询参数,写在 URL ? 后面的。
| 注解 | 位置 | 例子 |
|---|---|---|
@PathVariable |
URL 路径 / 里 |
/100/true |
@RequestParam |
URL 问号 ? 后面 |
?current=1&id=100 |
② blogService.query()
→ 翻译:我要查 blog 表(博客表)的数据
→ 等价 SQL:SELECT * FROM blog
③ .page(分页参数)
.page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
这是MyBatis-Plus 分页方法,两个参数:
current:当前页码(比如 1 = 第一页,2 = 第二页)SystemConstants.MAX_PAGE_SIZE:固定值,比如 10 → 一页显示 10 条博客
④ page.getRecords()
→ 翻译:从分页结果里,把「当前页的博客列表」拿出来
→ 结果:[博客1, 博客2, ..., 博客10]
(2) 修改FollowServiceImpl
改造原因:我们需要在用户关注了某位用户后,需要将数据放入到set集合中,方便后续进行共同关注,同时当取消关注时,也需要从set集合中进行删除。set集合可以实现交集、并集、补集的功能。
1 |
|
说明:
.collect(Collectors.toList())
把转换好的数字 ID,打包成一个列表
3. Feed流实现方案
针对好友的操作,采用的是Timeline的方式,只需要拿到我们关注用户的信息,然后按照时间排序即可,因此采用Timeline的模式。该模式的实现方案有三种:
- 拉模式
- 推模式
- 推拉结合
(1) 拉模式
① 核心逻辑:
当张三、李四和王五发了消息后,都会保存在自己的邮箱中。假设赵六要读取信息,那么它会从读取它自己的收件箱,此时系统会从它关注的人群中,把它关注人的信息全部都进行拉取,然后在进行排序。
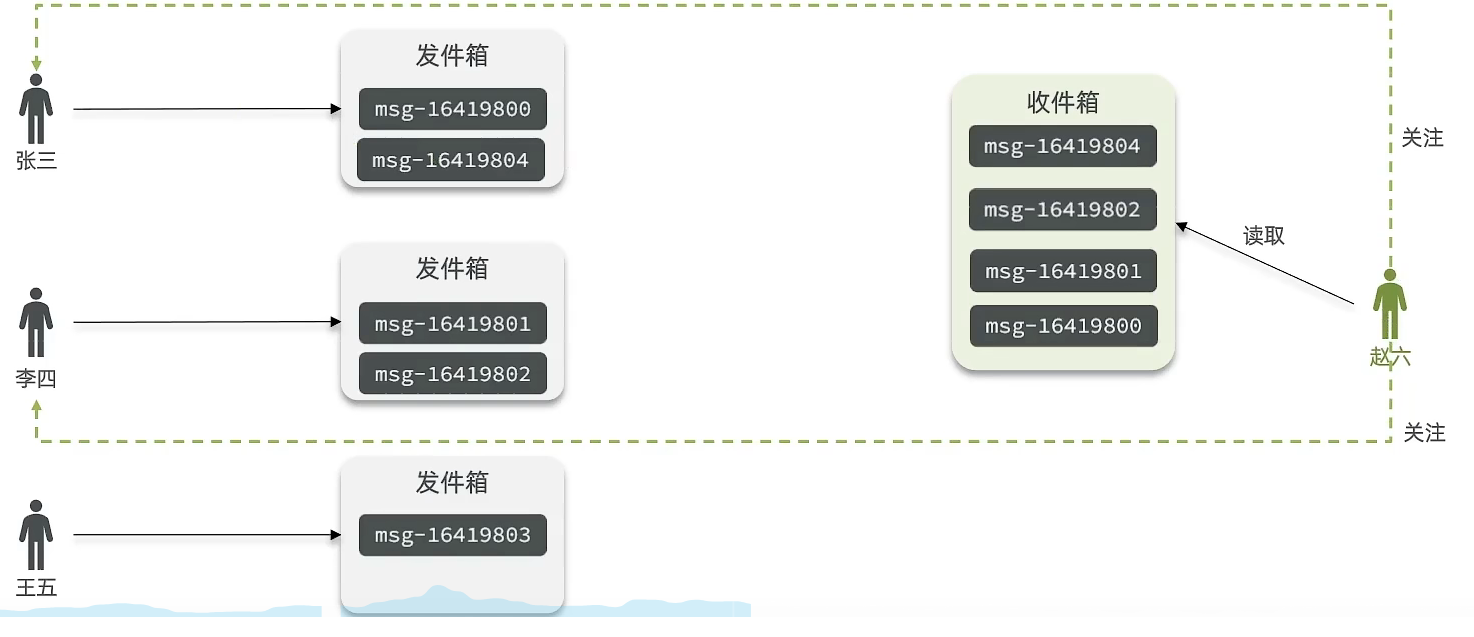
② 优点:比较节约空间,因为赵六在读信息时,并没有重复读取,而且读取完之后可以把它的收件箱进行清楚。
③ 缺点:比较延迟,当用户读取数据时才去关注的人里边去读取数据,假设用户关注了大量的用户,那么此时就会拉取海量的内容,对服务器压力巨大。
(2) 推模式
① 核心逻辑:
推模式是没有写邮箱的,当张三写了一个内容,此时会主动的把张三写的内容发送到它的粉丝收件箱中去,假设此时李四再来读取,就不用再去临时拉取了。
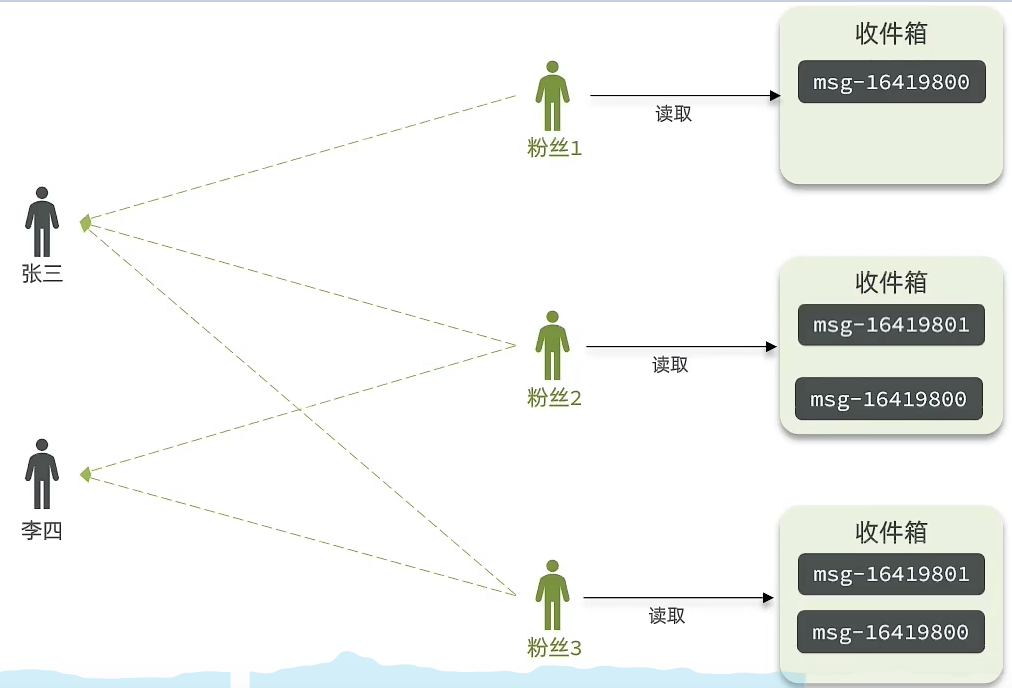
② 优点:时效快,不用临时拉取。
③ 缺点:内存压力大,假设一个大V写信息,很多人关注它, 就会写很多分数据到粉丝那边去
(3) 推拉模式
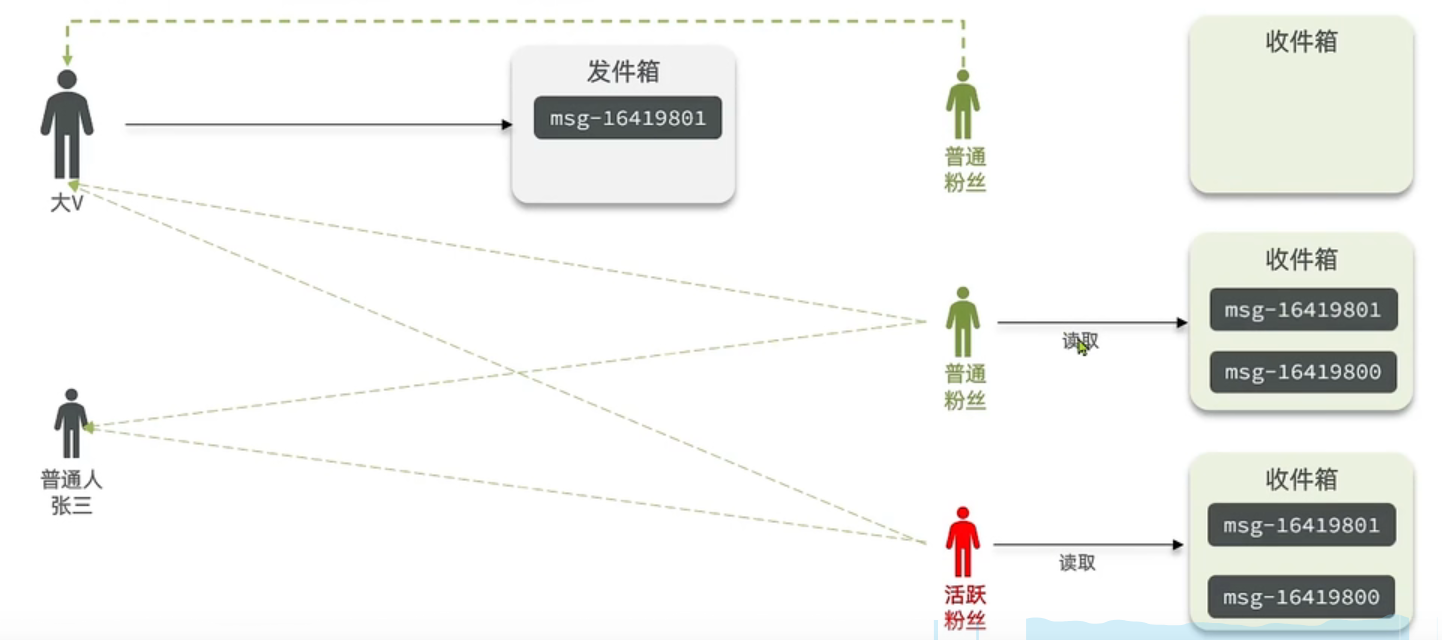
推拉模式是一个折中的方案。
① 站在发件人这一端,如果是个普通的人,那么我们采用写扩散的方式,直接把数据写入到它的粉丝中去,因为普通的人它的粉丝关注量比较小,所以这样做没有压力。如果是大V,那么它是直接将数据先写入到一份到发件箱里边去,然后再直接写一份到活跃粉丝收件箱里边去。
② 现在站在收件人这端来看,如果是活跃粉丝,那么大V和普通的人发的都会直接写入到自己收件箱里边来,而如果是普通的粉丝,由于它们上线不是很频繁,所以等它们上线时,再从发件箱里边去拉信息。
4. 推送到粉丝收件箱
(1) 需求
- 修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
- 收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
- 查询收件箱数据时,可以实现分页查询
(2) Feed流的分页问题
① 传统分页
- t1 时刻:取第 1 页(
page=1, size=5),拿到10,9,8,7,6。 - t2 时刻:新增一条内容
11,数据整体后移。 - t3 时刻:取第 2 页(
page=2, size=5),按传统逻辑从第 6 条开始取,拿到6,5,4,3,2。 - 结果:
6在第 1 页和第 2 页都出现了,数据重复。
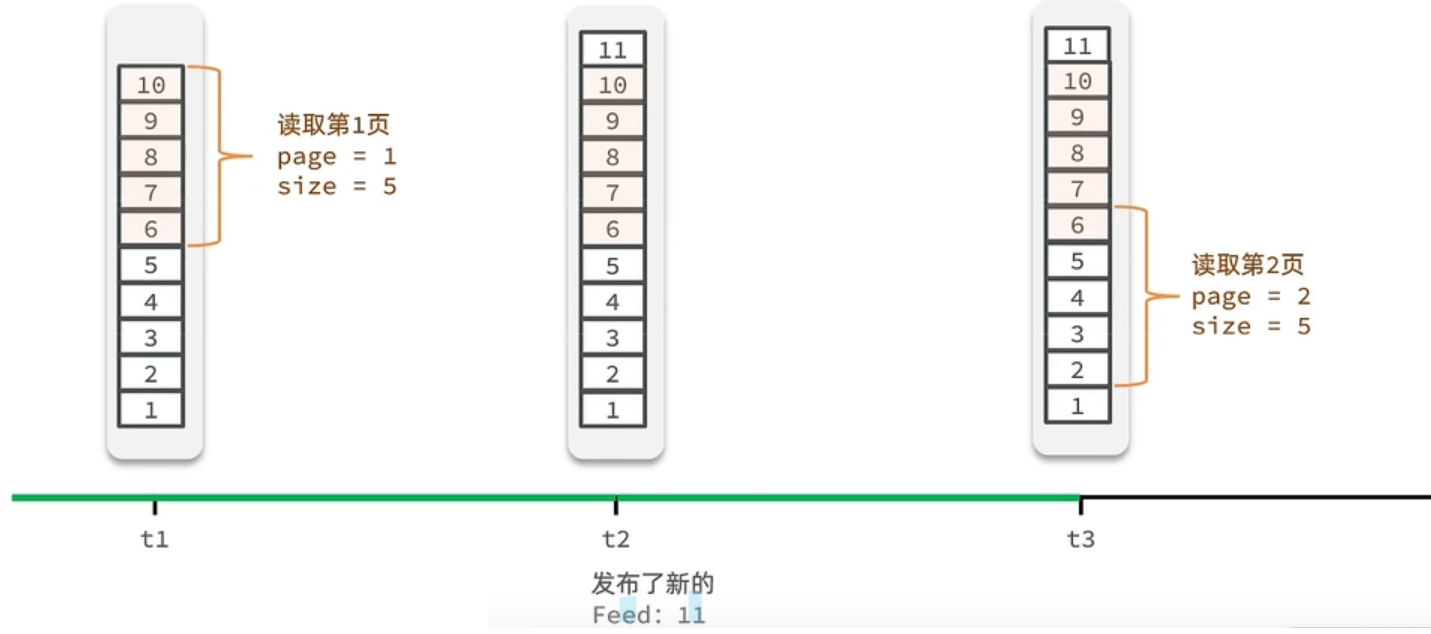
② 滚动分页
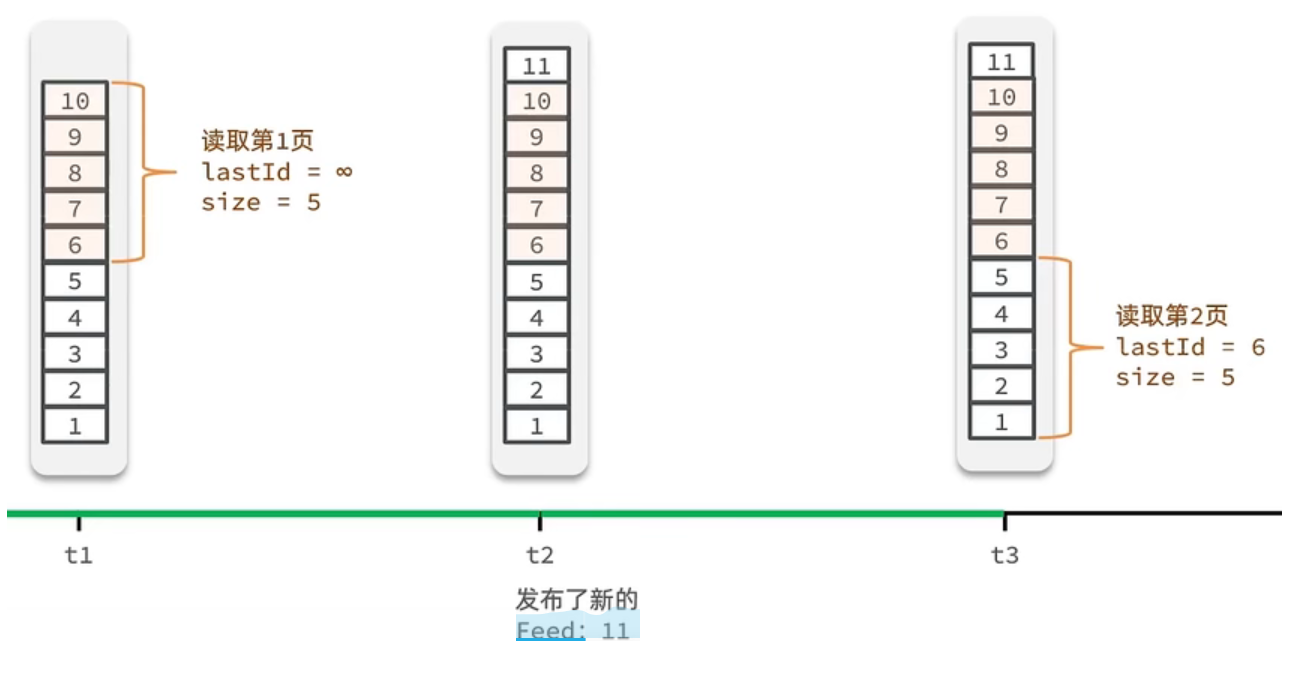
- t1 时刻:首次加载,
lastId = ∞(无前置数据),取前 5 条10,9,8,7,6,记录lastId = 6。 - t2 时刻:新增内容
11,插入到最顶部,不影响已记录的6。 - t3 时刻:加载下一页,传入
lastId = 6,从6之后的5开始取,拿到5,4,3,2,1,无重复。
(3) 代码实现
1 |
|
5. 实现分页查询收邮箱
(1) 需求
① 每次查询完成后,我们要分析出查询出数据的最小时间戳,这个值会作为下一次查询的条件
② 我们需要找到与上一次查询相同的查询个数作为偏移量,下次查询时,跳过这些查询过的数据,拿到我们需要的数据
| 参数 | 含义 | 核心目的 |
|---|---|---|
lastId |
上一次查询结果里的最小时间戳 | 限定本次查询只加载「比这个时间更早」的 Blog,保证数据按时间倒序加载,避免重复获取 |
offset |
上一次查询返回的Blog 数量 | 用来跳过已经加载过的数据,实现 “下一页” 的翻页效果 |
(2) 代码实现
① 定义出来具体的返回值实体类
1 |
|
② BlogController
1 |
|
③ BlogServiceImpl
1 |
|
说明:
① List
List<Long>:创建一个列表,里面专门存 数字类型的博客 ID(数据库里的 ID 是数字,不是字符串)ids:列表的名字,意思就是 id 集合new ArrayList<>():创建列表对象1
typedTuples.size()
:
提前指定列表的大小
- 比如 Redis 查到了 2 条数据,列表就直接开 2 个位置
- 作用:优化性能,不用让列表自动扩容
② String idStr = tuple.getValue(); ids.add(Long.valueOf(idStr));
tuple:循环中每一个 Redis 包裹(包含博客 ID + 时间戳)tuple.getValue():拿出包裹里的博客 ID(注意:是字符串格式,比如 “1001”)1
Long.valueOf(idStr)
:
把字符串 ID 转成 数字 ID
- 因为数据库里的 ID 是
Long数字类型,字符串查不到数据,必须转类型
- 因为数据库里的 ID 是
ids.add(...):把转换后的数字 ID,放进刚才创建的列表里
③ List
1). 问题
Redis 查出的 blogId 是按时间倒序的,但 MySQL 的 IN 查询不会保证返回顺序!直接查会导致博客顺序乱掉。
2). 解决方案
ORDER BY FIELD(id, 1,2,3):强制让数据库返回的顺序 和 Redis 中的 id 顺序完全一致,保证前端展示顺序正确。
附近商户
1. GEO数据结构的基本用法
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
- GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
- GEODIST:计算指定的两个点之间的距离并返回
- GEOHASH:将指定member的坐标转为hash字符串形式并返回
- GEOPOS:返回指定member的坐标
- GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.以后已废弃
- GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
- GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。6.2.新功能
2. 导入店铺数据到GEO
(1) Redis GEO 数据结构设计
① 按「商家类型」分组存储
Redis GEO 本身不支持额外的类型筛选条件(比如只查美食、排除 KTV),所以我们用分组来解决:
给每种商家类型建一个独立的 GEO 集合,Key 格式为:
1
shop:geo:{类型}
- 美食类:
shop:geo:美食 - KTV 类:
shop:geo:KTV
- 美食类:
这样用户选「美食」时,直接查询
shop:geo:美食,天然就过滤了类型,只查美食商家。
② GEO 里只存「商家 ID」,不存完整信息
Redis 是内存数据库,存太多数据会占满内存,所以:
- Value(member):只存商家的ID(比如海底捞的 ID 是 1,就存 “1”)
- Score:Redis 自动把经纬度转换成 GeoHash 值,用来计算距离和排序
- 完整的商家信息(名称、地址、评分等)依然存在数据库(MySQL)里,之后用 ID 去查。
(2) 代码实现
1 |
|
说明:
① Map<Long, List
- 用
groupingBy(Shop::getTypeId)把所有店铺,按类型 ID分成一组一组; - 最终得到一个
Map:key = 类型 ID,value = 该类型的所有店铺; - 后续给每个类型创建一个独立的 Redis GEO Key(比如
shop:geo:1是美食店,shop:geo:2是 KTV),查询时直接查对应 Key,天然过滤类型。
② 往箱子里「装每个店铺的包裹」
1 | for (Shop shop : value) { |
shop.getId().toString():把店铺 ID 转成字符串,作为 Redis GEO 里的member(相当于快递单号,用来后续查询店铺信息)new Point(shop.getX(), shop.getY()):封装店铺的经纬度
3. 实现附近商户功能
(1) ShopController
1 |
|
(2) ShopServiceImpl
1 |
|
说明:
① .page(new Page<>(current, 每页条数))
current:前端传的当前页码(比如第 1 页、第 2 页)SystemConstants.DEFAULT_PAGE_SIZE:每页默认显示多少条店铺(比如 10 条)
② return Result.ok(page.getRecords());
Page 分页对象里包含了很多分页信息:
- 总页数、总条数、当前页、每页条数、数据列表
getRecords()= 获取分页查询到的「店铺数据列表」(就是我们要展示给用户的店铺集合)
③ 指定类型 + 5 公里范围内 + 按距离排序 的店铺
| 参数 | 代码写法 | 大白话翻译 |
|---|---|---|
| 第 1 个 | key |
查哪种类型的店铺(比如美食店) |
| 第 2 个 | GeoReference.fromCoordinate(x, y) |
以用户当前坐标为圆心 |
| 第 3 个 | new Distance(5000) |
以圆心为中心,画 5000 米(5 公里) 的圈 |
| 第 4 个 | includeDistance() |
必须计算并返回每个店铺离用户的距离 |
| 第 4 个 | limit(end) |
最多查 end 条数据(分页用) |
④ Map<String, Distance> distanceMap = new HashMap<>(list.size());
distanceMap:一个空 Map- 作用:等会儿存 “店铺 ID → 离你多远”
- 比如:
105 → 1.2km
⑤ shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());
.getValue() 的作用是从 Distance 对象里,提取出纯数字的距离值(比如 1.2),Distance 对象是 Redis 封装的,包含单位、数值等信息,我们只需要数值给前端展示




